Monorepo 不是一个新话题了,这个概念最早被 Google 提出,指的是将所有项目代码(无论是前端、后端、库、工具等)集中存放到同一个仓库中,打个比喻就是把我们现在的 Java 应用、前端 JS 和组件库都放在同一个仓库中,再通过工程自动化在发布过程做分离。
发展到如今已经有非常多的公司采用这种方式进行该种方式管理代码,随后也发展出来非常多针对 Monorepo 场景下的工具链,如:Nx、Lerna、Turborepo
使用现状
Monorepo 在我们团队内部其实已经有许多项目已经在应用,为此我们还专门做过一期当前 Monorepo 解决方案的对比分享(😑 很遗憾没有做视频录制,只能晒几张 PPT 感受一下)。




最终我们确定了 Turborepo + Pnpm + Changesets + SWC 的最终方案,除此以外还整合开发了 O2(内部云构建平台) 的多包云构建链路,解决了 按需发布、编译缓存、workspace: 前缀转换、pnpm 依赖缓存 等多项集团基建的差异问题。使得我们的 Monorepo 也可走 O2(内部云构建平台) 的标准化变更流程(CR、多主干、需求绑定、集成分支)
当前团队中主要是 LAGO(内部平台) SDK、源码开发脚手架,组件库开发脚手架 等项目在投入生产使用该方案,并且从开发效率和开发体验来讲均得到了非常不错的反馈。
所以,为什么这几个库非常适合使用 Monorepo?
- 消费场景多样,在前端工程化建设部分,现在在集团中,一个比较完整的套件应该提供 开发时套件(dev\test\build)、云构建、O2(内部云构建平台) 模块管理(套件灰度发布、套件行为监控、套件强制升级),这类场景的消费产物都是 NPM 包,但相互又存在非常多的复用逻辑,Monorepo 则可以很好的管理代码
- 插件化消费场景,LAGO(内部平台) SDK 则需要提供不同的插件模块以供开发者安装不同中间件进行站点能力组合,配合 LAGO(内部平台) 平台进行 PaaS 能力组合。如:模块、OSC、子站点 均是可被单独选用安装的 LAGO(内部平台) 插件,这些 SDK 通过 Monorepo 管理则可以做到便捷的 代码复用 和 版本变更。
- 紧密关联,这几个项目都是相互关联、相互依赖的。它们共同都在服务同一个场景下的需求,在 Monorepo 下,可以更高效地共享代码、工具和配置,确保整体的一致性。
- 规模适中,这几个项目的规模都比较适中,Monorepo 非常适合这种中小规模的多项目组合,这样既能发挥代码共享等优势,又不会过度膨胀导致性能问题。
BTW,这里我顺便个人认为不应该使用 Monorepo 的场景,组件库。虽然表面看来起来,组件库也是紧密相关,如果是 Monorepo 形式的话用户可以按需选用,看上去好像是个不错的选择。但有编译的存在,Tree Shaking 可以更好的完成按需编译的基本诉求,组件库拆分成单个组件的 NPM 反而会增加组件的管理成本。所以我认为如果消费侧是纯粹的 NPM 包,不应该选用 monrepo。(当然有天马的存在,组件库的消费方式很多在 C 端的场景是 CDN 方式,这个就另当别论了)
更进一步,业务开发
在评估新技术引入的过程中,一定是慎之又慎,否则就像我上面提到的案例一样,不但没有为团队带来提效,反而有可能引入非必要的复杂度。
虽然我们可能无法直接做到像 Google 那种一个仓库包含后端、前端、组件库,几百人在同一个仓库进行项目开发。但我们是否有可能在业务的前端项目开发中引入,并解决一些实际的协同问题呢?
许多时候其实不是问题不存在,而是问题随着我们的适应而变得视若无睹
在我们当前 LAGO(内部平台) + MPA 的基本架构下,虽然已经能够应付绝大多数场景下的业务需求。但是这也使得我们的仓库数量激增,截止目前 builder-asc-page(源码构建器) 服务仓库数量 526 个,builder-vite-comp(组件构建器) 服务仓库数量 178 个。每一次技术栈的升级,每一次大改版的升级,我们大概率都会采用新的仓库进行渐进式升级。
这样做的问题并不是在于这些仓库的数字激增有什么不好,问题是在于这背后数字的激增所带来的无形的隔离墙和割裂感。团队成员很可能除了初始化模板的时候会看看模板里面写的代码是什么样子,以后的所有迭代开发都只会关注到自己已知的知识体系内,从仓库层面就断绝了代码复用,借鉴学习的可能性。
工程化设计面临的很大挑战就是在于平衡 中心化 和 非中心化,过渡集中引发问题,过渡分散也会有新的问题,甚至每个阶段的平衡都是不一样的。
所以,Monorepo 如果引入常规的业务需求开发中,能否会为 中心化 和 非中心化 找到新的平衡点呢?
当前,我们的业务开发受整体 B 端架构影响,主要采用 assets 模式发布 CDN 资源,对于纯页面需求来说其实是够用的,但在业务交付的背后却也存在诸多不合理的问题,我找到几个:
- 同一个域不同仓库,商品发布和商品管理应该来说是很紧密的业务关系,其中应该有很多的逻辑复用,但目前却是分开的两个仓库。类似的事情还发生在其他一些业务域,仓库过于分散,关注度过于细微,产品割裂感强烈。
业务组件规模增长缓慢,虽然我们提供了非常方便的 MC 组件方案,但除了部分有被要求的域有过类似的业务组件沉淀,其他的域不到万不得已不会轻易拆库,原因在于会增加项目的维护和变更成本。商品价格和库存编辑又是一个独立的仓库,因为在货品运营部分的页面也需要调用到商品的价格编辑能力。但当价格和库存编辑抽离成独立包后,又会对商品管理的迭代带来新的变更成本。同样问题的还有类似 Price Lock、Bidding 等 Widget + 落地页的场景。
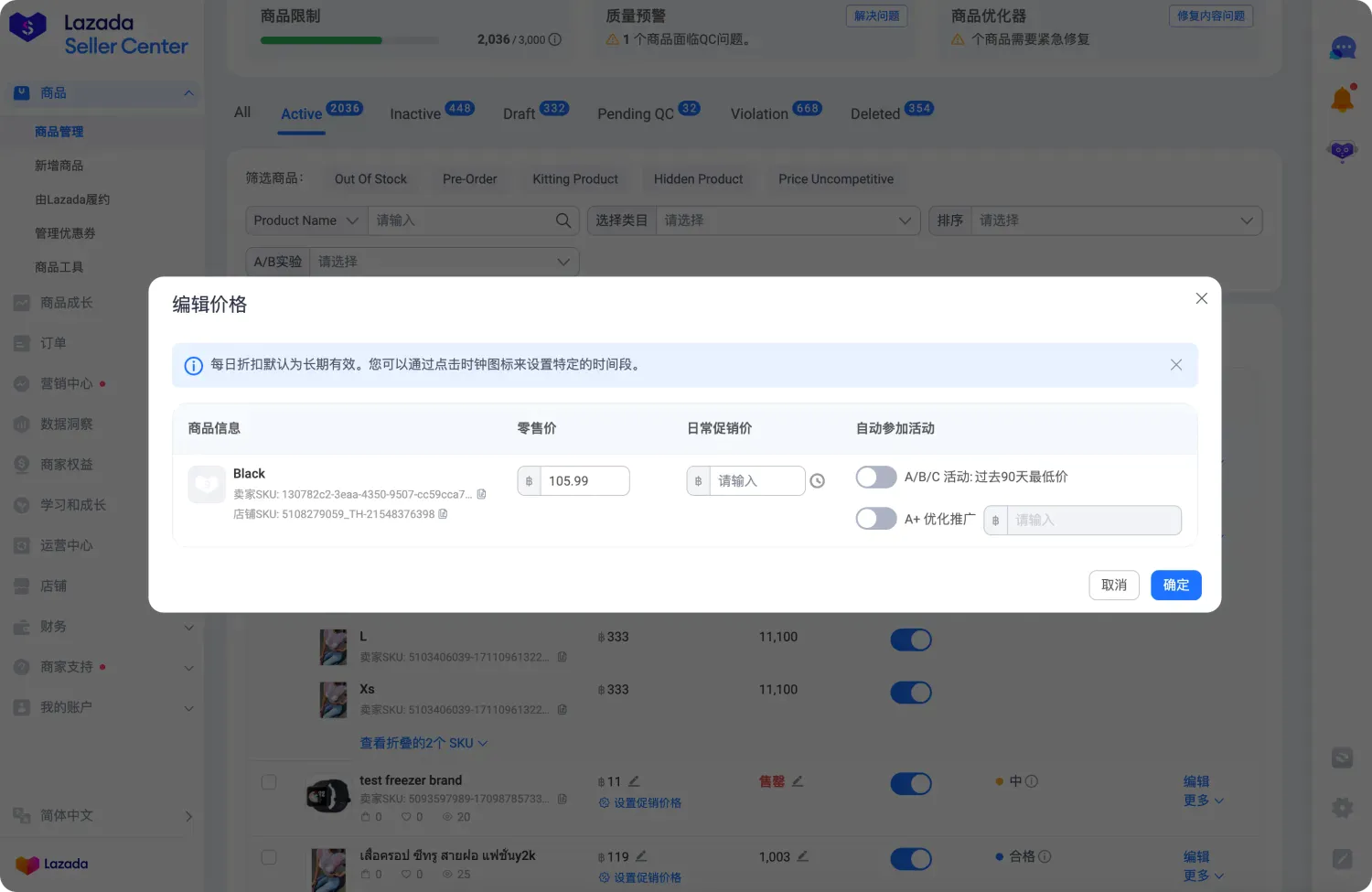
多端业务问题频发,目前我们团队在部分业务承接包含 PC + APP 的双端支持,在这类业务中,都面临着业务逻辑相同,UI 和 交互 却有差异的挑战,由于技术栈和构建器的差异,却不得不将其拆分为多仓库,如果有相同的业务逻辑要么拷贝,要么抽离 NPM。当有新的业务迭代时就会出现评估影响范围缺失、变更不同步、数据处理有差异等问题。
- 交付内容“不持久”,Formily 改造表单叫重构,Fusion 换到 Antd 叫重构,大的 UI 交互迭代也叫重构。但凡涉及到依赖变更、构建器变更,都只能新启一个仓库和 O2(内部云构建平台) 应用,之前的许多逻辑均需要一个个甄别然后拷贝回来,似乎我们交付的产品“保鲜期”都比较短。其实这些都只是部分模块需要迭代而已的,但却因为工程化的不合理导致需要进行仓库迁移。
这些问题都是被掩盖在日常迭代的业务需求下面的架构问题,我们的同学长期在这样的架构环境下,可能会缺乏全局视角、缺乏业务深度、缺乏产品意识,甚至影响到积极性。
之前很长一段时间,我们前端架构设计的基本思路,是简化简化再简化,全局状态、动态主题、多语言、前端路由、工程化配置、CI\CD、模块拆分,把这些复杂的东西都收拢后,给出一个统一的解决方案甚至是模板,这会导致我们的同学难以遇到较为复杂的前端问题,进而导致见识广度和思考深度不足。

所以,即便是在减少复杂度这件事情上,也不见得都是好的。尤其在基建架构设计上,我们所面对是有专业知识的工程师,有时候我们需要刻意留下部分原理和灵活度,尽量让事情变得白盒化,让开发者可以充分发挥他们的潜在价值。
如果在业务开发中引入 Monorepo 的可以说从工程架构(构建器、脚手架)、管理架构(业务域划分)上面都提供了更灵活的组合方式,团队内部则可以从单名作战的状态转换到以团队为单位的状态,团队之间的交流、评审应该可以显著增加,从而提升交付质量。
但我个人对于超大 Monorepo,几百个人在同一个仓库上工作,还是持谨慎态度。在前期的试点过程中,我们应尽量控制在 3~10 人的数量,以业务域为单位推进为好。
所以总结一下,引入 Monorepo 架构在业务前端项目开发中可以带来以下一些收益:
- 促进代码复用和知识共享
- 减少仓库过度分散带来的割裂感
- 解决多端业务开发的效率问题
- 提升交付内容的”持久性”
- 促进全局视角的培养
- 提高团队协作 (Monorepo 有利于以团队为单位的协作模式,提高团队内部交流、评审质量)
方案:像 Apple Vision Pro 一样的融合
所以,在想清楚了 Monorepo 带来的收益后,我们考虑一下应该如何来实现。
首先,在各个垂直领域,我们已经有许多相关沉淀:
- asc-toolkit 专注于开发和构建源码页面的统一脚手架
- vite-comp-toolkit 专注于开发和构建物料库的统一脚手架
- changesets 使用 pnpm + changesets + Turborepo 专注于 Monorepo 仓库 O2(内部云构建平台) 发布
也就是说,目前来讲我们已经具备了各领域下的垂直解决方案。在新的 Monorepo 的方案下,目标是:做到在一个仓库中同时支持上面 3 种解决方案,做到像 Apple Vison Pro 一样的丝滑融合。
要做到这一点我们可能会面对以下几个问题:
1. 按需还是全量?
在 Monorepo 模式下,既可以有 NPM 类型的包,又可以有 bundle 类型的 assets 资源,当一个仓库存在非常多个包内容的时候,每次迭代是否需要对所有子包都做编译发布。
1.1. 全量发包
全量发包,社区采用该种方式发包的项目有:Formily、Storybook 等,他们的特点是相关性较强,用户使用这类仓库的时候往往需要连续安装多个相关仓库,如果需要升级,需要统一升级,防止影子依赖,出现上下文异常等问题。
优势
- 管理简单,可直接根据 O2(内部云构建平台) 的迭代版本号全量发版,所有版本号与 O2(内部云构建平台) 的迭代号保持一致,下游使用非常方便;
- CI 逻辑简单,所有包要升都升,不需要复杂的版本升级计算;
- 开发者无感知,开发者还是可以按照原有 O2(内部云构建平台) 常规流程进行迭代开发,最终 NPM 发布版本以 O2(内部云构建平台) 迭代号版本为主;
劣势
- 变更范围不精准,会出现很多不必要的发布,如果是一个 NPM 为主且相关性不大的仓库(如 Merlion 系列),则会出现非常多的零变更发布;
- 发布效率低下,因为是全量发布每次变更都需要对所有包做编译,大型项目中可能会引起编译时间过长等问题;
1.2. 按需发包
按需发包,是社区 Monorepo 采用的主流管理方式,采用该方式的项目有:Vite、Babel 等,他们的特点是以 NPM 为主,通过如 Lerna、Changesets、Nx、Bumpp 等脚本工具,精准控制版本升级。
当我们对某个包进行更改时,使用 ^ 和 ~ 的影响如下:
- 使用 ^ 配置
如果一个包的依赖包使用 ^ 配置,例如 “dependency”: “^1.2.3”。当我们更新了被依赖包的次版本号时(如从 1.2.3 升级到 1.3.0),依赖它的包也需要发布新版本以获取更新。 这是因为 ^ 的语义是接受当前主版本号下的任何次版本升级,所以被依赖包从 1.2.x 升级到 1.3.x,依赖它的包也需要发布以获取这个更新
- 使用 ~ 配置
如果一个包的依赖包使用 ~ 配置,例如 “dependency”: “~1.2.3”。那么只有当被依赖包的修订号发生变化时(如从 1.2.3 升级到 1.2.4),依赖它的包才需要发布新版本。
这是因为 ~ 的语义是只接受当前次版本号下的修订号变化,所以被依赖包从 1.2.3 升级到 1.2.4 时,依赖它的包需要重新发布以获取补丁更新。
优势
按需发包的优势很多,简单来说它相当于利用工程脚本完成了多个仓库的管理,本质上这种方式和原先多仓的发版方式没有区别,只是我们可以利用工具准确无错的完成整个变更动作。所以这种方式是基本无副作用的整合多个包到一个仓库的最佳实践,精准控制发布范围,发布效率高,版本控制灵活。
劣势
- 按需发布也存在一些劣势,首先是需要学习相关的命令和背景知识,准确配置 Semver 依赖版本,否则使用者可能会稀里糊涂的出错(比如发了 a 包为什么 b 包也被发了,c 包又没被发布;比如为什么发 beta 版本的时候会发 6 个,发正式版本的时候却只发了 1 个);
- 每次变更需要有额外动作,相比与 O2(内部云构建平台) 的无脑下一步,使用按需发布时,开发者需要明确感知每个 package.json 的变化;
- CI/CD 困难,相对于单包发布或者全量包发布,按需 Monorepo 发布的 CI/CD 过程会更加困难,需要用户在本地先行确认需要发布的包版本,然后通过构建器识别后,完成按需发布,不同于本地发布,可以一个命令跑完所有流程,像 changesets 这类版本管理工具就需要有:1. changeset 确认升级包范围(major\patch); 2. version 执行写入 package.json 变更; 3. publish 根据用户使用的 packageManager 执行包发布;
1.3. 实际场景代入
综上所述,按需发包和全量发包均有其优势和使用场景,下面通过一些实际场景来举例说明:
Merlion XX (按需发包)
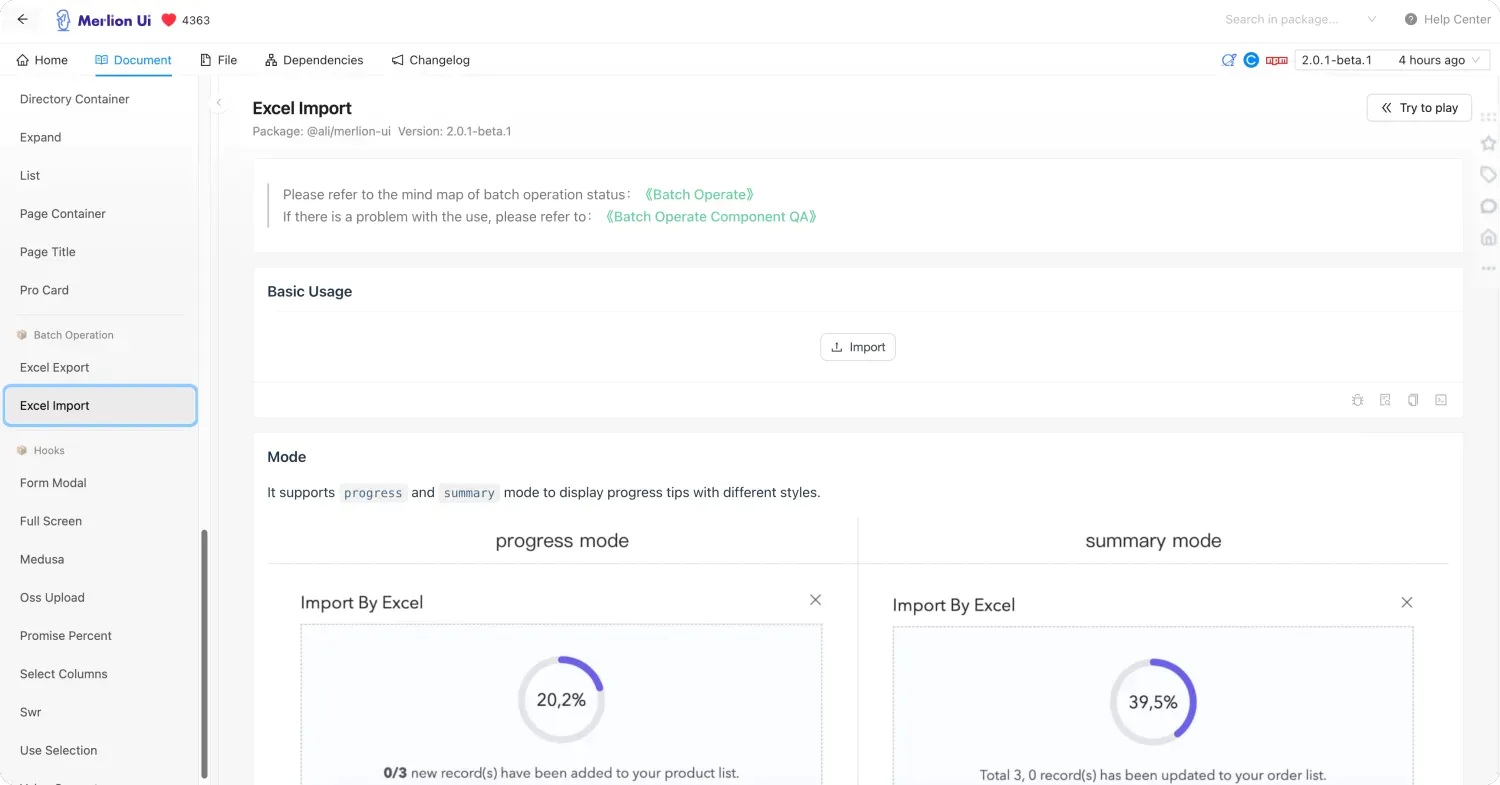
Merlion 系列作为我们组件库的基础沉淀,其中有许多部分是存在逻辑重复的,比如 hooks、数据处理(地址、Medusa)、逻辑处理(导入导出),如果我们将 Merlion UI、Merlion Mobile、Merlion Hooks 合并做成 Monorepo 方式进行管理,则可以大大提升迭代发版的便利性,也可以降低迭代过程中的遗漏风险。
如果要对 Merlion 系列做 Monorepo 的版本管理,则应该采用按需发包的模式。
首先,Merlion UI 与 Merlion Mobile 只是有部分逻辑存在重合,但对于消费方差异很大,并且作为一个基础依赖,我们需要非常谨慎的控制其变更范围。
其次,Merlion UI 这类组件库,在变更过程中,会有 Semver 版本号规范的要求,目前 Merlion UI 就有 Fusion、Antd 双主干、大版本号的区分,而 Merlion Mobile 则没有,按需发布可以更灵活的控制版本变更和影响范围。
商品基础 (全量发包)
商品基础作为 ASC 的一块业务领域,目前商品管理、商品发布、价格编辑、批量编辑等均存在复用逻辑,其中价格编辑、库存编辑还将作为 模块SDK 开放给其他业务使用。
这类相关性极强,并且以 CDN 产物交付为主的仓库,消费链路可控,并且对功能一致性有较高要求的,则可以采用全量发包的形式,直接根据 O2(内部云构建平台) 迭代版本号定义包版本号 和 CDN 资源版本号。
这样在整条消费链路上都比较容易对齐,并且变更发布的操作路径更之前 Assets 类型发布也没有差异,比较容易在业务开发中推广和落地。
2. PNPM 云构建支持
Monorepo 的包管理工具其实有非常多的选择,目前 tnpm \ yarn \ pnpm 等基础包管理工具也均对 workspace 做了支持。
在包管理工具的技术选型上面,之前做过相关的对比和调研,最终结论是:Turborepo + Pnpm + Changesets 这样的租户,也是目前社区目前主流认为的,关于 Monorepo 实践的最佳实践,这里不做展开。
主要需要目前来解决的问题是集团基建目前对这种超前技术的支持度不足,需要我们来解决以下一些问题:
- 不支持 pnpm 依赖缓存,O2(内部云构建平台) 在 23 年末终于支持了对 node_modules 的缓存支持,大大节省了各种仓库 install 的耗时,但在 pnpm 这块还不支持(怀疑是硬链接的方式导致),需要通过 postinstall 中处理
pnpm install --offline来重新建立硬链接。 - Workspace protocol,Workspace protocol 是目前许多包管理工具对于 Monorepo 仓库的子依赖什么的一种新协议,目前 yarn \ pnpm 中均有很好的支持。但目前如果通过 tnpm 发布的包,并不会修改
workspace:的前缀,这会导致消费端在安装时直接报错 🐶
3. 构建器调度
对于本地发版的 NPM 项目,接入 Monorepo 其实就只是接入一些 Monorepo 的解决方案即可,比如 Nx、Lerna 这些,但如果需要全面覆盖到业务开发中,则需要接入 CI\CD 这相对于本地一把梭,就会是一个相对复杂的工程化建设。
首先,根据上述论证,将会同时支持 全量发包 和 按需发包 两种模式,在 abc.json 中让用户自行配置:
{ "builder": { "name": "@ali/builder-changesets", "config": { /** * 是否覆盖 def 迭代号作为发布版本 * 当 manual 为 false 时,此配置无效 * @default false */ "useO2(内部云构建平台)Version": true, /** * 是否手动选择发布包 * false 则使用 O2(内部云构建平台) 迭代号全量发包 * @default false */ "manual": false } }}默认配置将使用 O2(内部云构建平台) 迭代号作为版本号执行全量发包,这样的配置方式用户的上手成本最低。并且也是大部分业务需求应该需要使用的模式。
其次,需要继续保持子构建器的中心化管理。之前我们在构建器中统一控制了部分构建逻辑,借助构建器的灰度版本控制,实际应用效果非常不错。在多语言提取、Antd 升级、Vite 模式扩展等多个项目中起到了非常大的作用。
在 Monorepo 的模式下,之前的单个构建器灰度逻辑控制将会出现问题,我们需要沿用之前的子构建器构建能力,并且有能力继续使用这种中心化管控的能力进行产物构建。
比如:builder-asc-page 与 builder-vite-comp 两个种类型的构建逻辑,在合并进入同一个 Monorepo 后,他们的构建逻辑依旧是受到统一的版本管控的,当 builder-asc-page 升级的时候,Monorepo 的此类构建逻辑依旧能够享受到升级,同理灰度、回滚也是。
4. TNPM 多包迁移差异
受到 O2(内部云构建平台) 目前所支持的能力限制(TNPM 多包),在 Monorepo 模式下目前只能支持以 NPM 为维度进行发布,并且采用 dist 文件 CDN 同步的方案。
所以通过 Monorepo 模式的 CDN 发布路径前缀为 /code/npm/{package_name}/{package_version}
而 Assets 类型的发布路径为 {group}/{project}/迭代版本号
从 Assets 类型项目到 TNPM 多包项目的变更,需要多配置一个 packageName,并且需要保证该 packageName 是唯一路径。
5. 编译缓存
在 Monorepo 中,一个很常见的问题是每次 build 构建或者 dev 启动都需要完成全部包的编译,并且编译顺序是需要根据依赖关系进行算法调度。
比如 a 依赖 b,当 a 需要 dev 启动时,应该保证 b 已经完成了 dev 的编译,因为在 b 中定义的 main 是编译后的产物路径,如果在 a 启动的时候,b 还没有完成编译,则会报编译报错,因为依赖项产物不存在。
好在 Turborepo 帮我们很好的解决了这个问题,我们只需要无脑启动即可,除了编译顺序以外,基于 Rust 的Turborepo 还可以实现并行编译、HASH Cache 等高效算法加快我们的启动和编译速度。
得益于 Turborepo 的先进调度和缓存能力,我们可以轻松、(超级)高效的处理 Monorepo 在复杂依赖关系下的编译过程。
以下做一个对比数据,17 个包的仓库,在 M2 MacBook Pro 上均采用简单的 Babel 编译的速度对比:
| 无并行,无缓存 | 并行 + 缓存 |
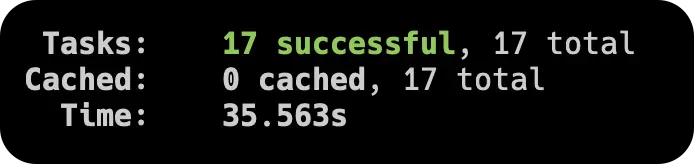 |  |
另一个好消息是 O2(内部云构建平台) 近期也支持了 编译缓存 能力,用户通过配置 abc.json 即可持久化缓存结果,在下一次编译的时候 O2(内部云构建平台) 会自动拉取上一次的 Turbo Cache,加速 Monorepo 下的构建速度,从而做到精准高效构建。
{ "buildCacheConfig": [ { "buildCachePath": "node_modules/.cache/turbo", // 编译缓存路径 "cacheKeyDependencies": [] } ]}云构建器,目前也在处理统一通过云构建器下发编译缓存配置,达到默认为构建器用户提供编译缓存能力,但目前协议还在调整,近期更新后,应该可以做到无感体验编译缓存加速构建
有了 编译缓存 + 依赖缓存,Monorepo 的云构建方案甚至可能快于原来的单仓库表现。
计划:渐进式升级
目前方案已经初步就绪,LAGO(内部平台) SDK 已经采用该工程链路进行开发管理。
接下来会通过以下几个项目的实践落地,进行验证调优
- Merlion UI + Merlion Mobile + Merlion Hooks
- 商品基础域 (商品发布 + 商品管理 + 批量发品 + 价格库存编辑)
- 首页模块 (首页落地页 + 各模块)