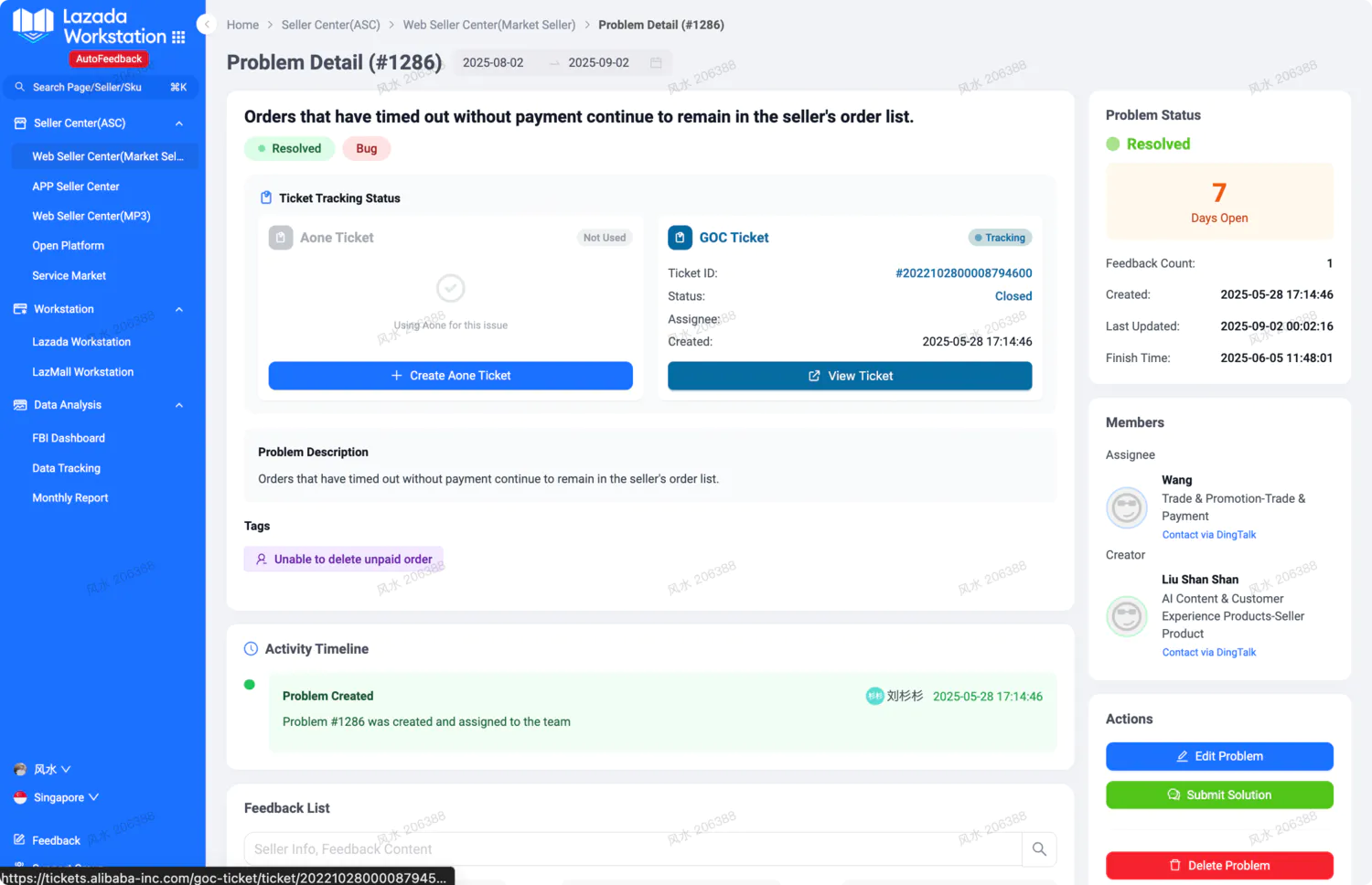
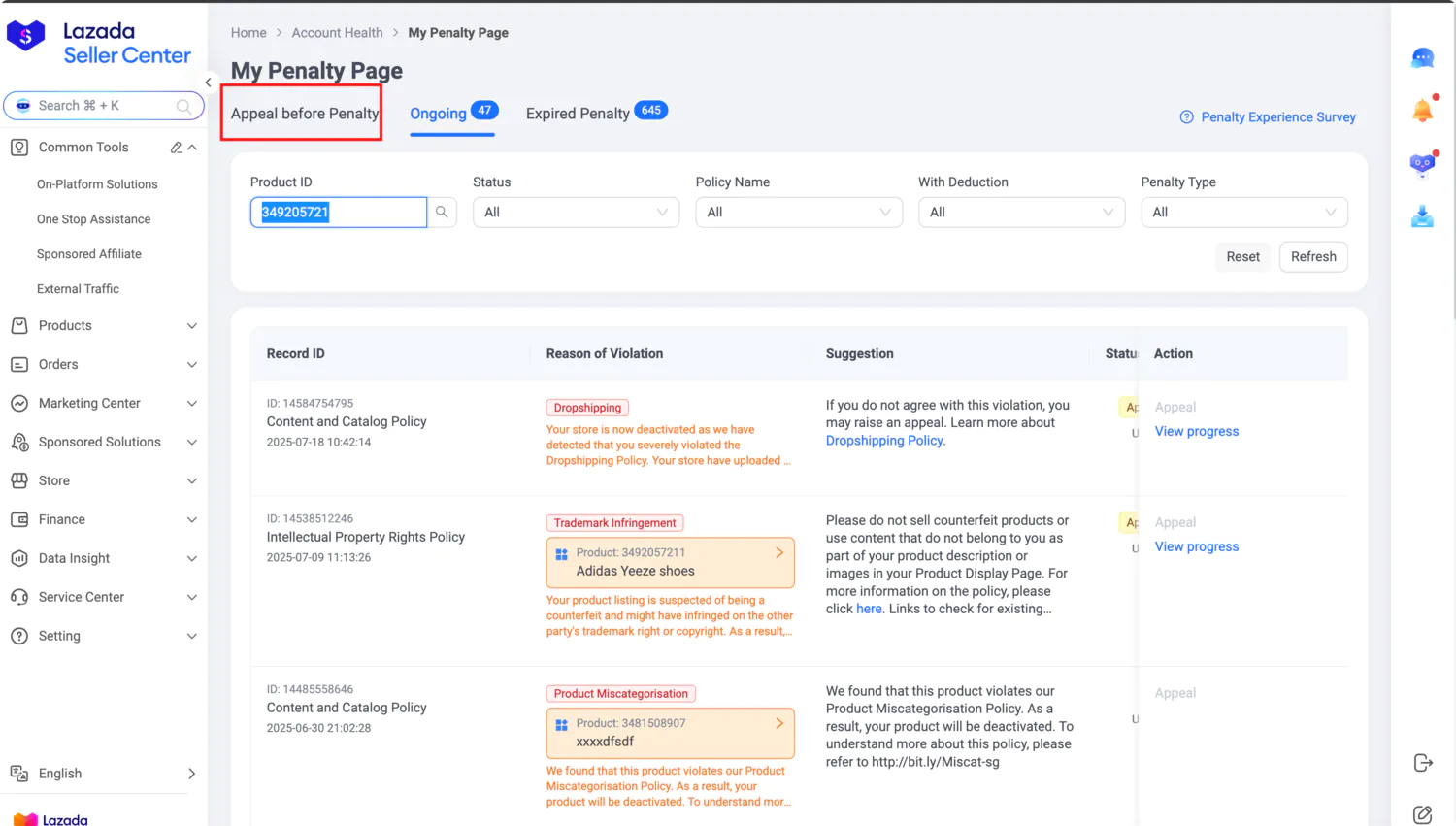
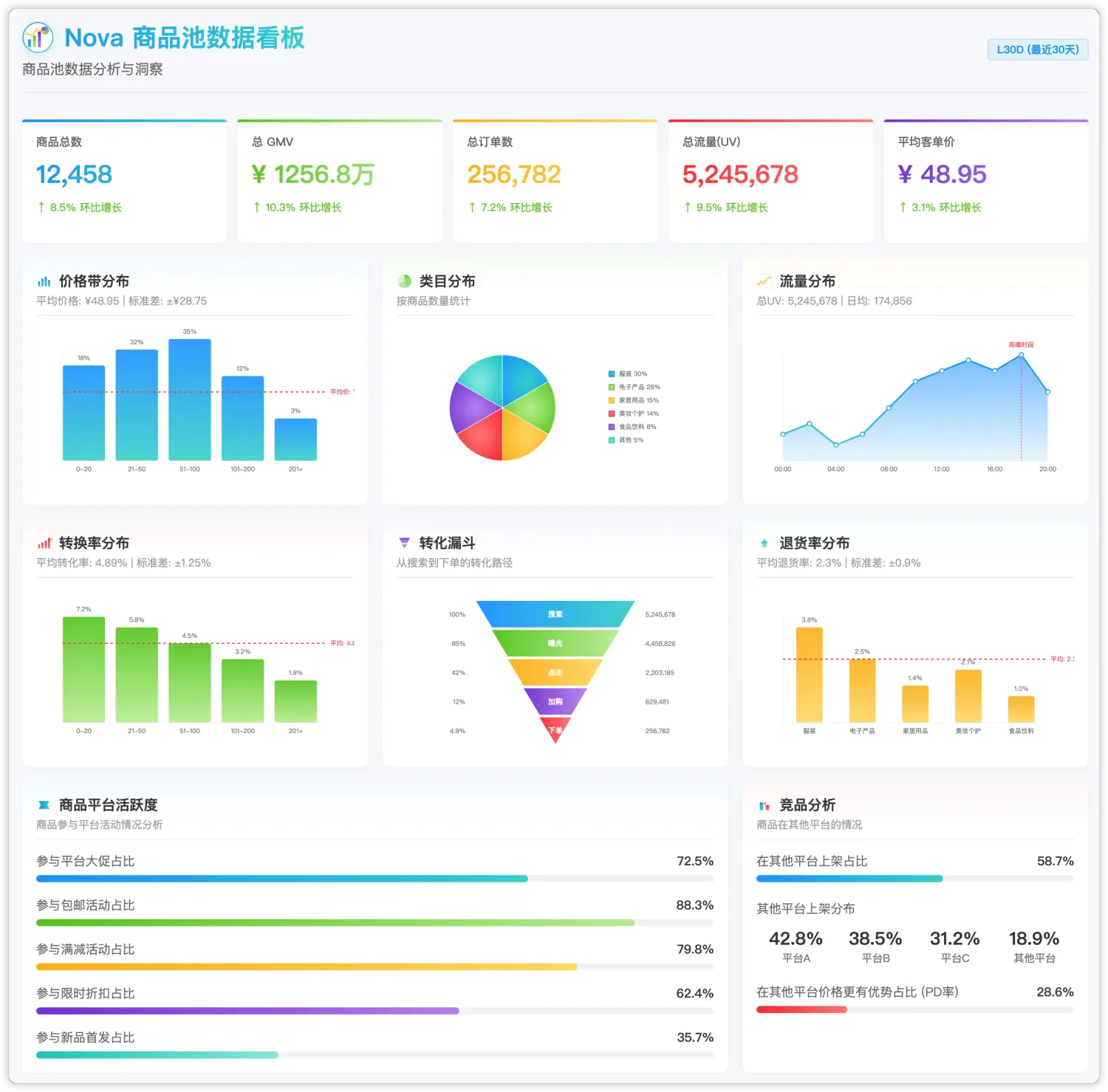
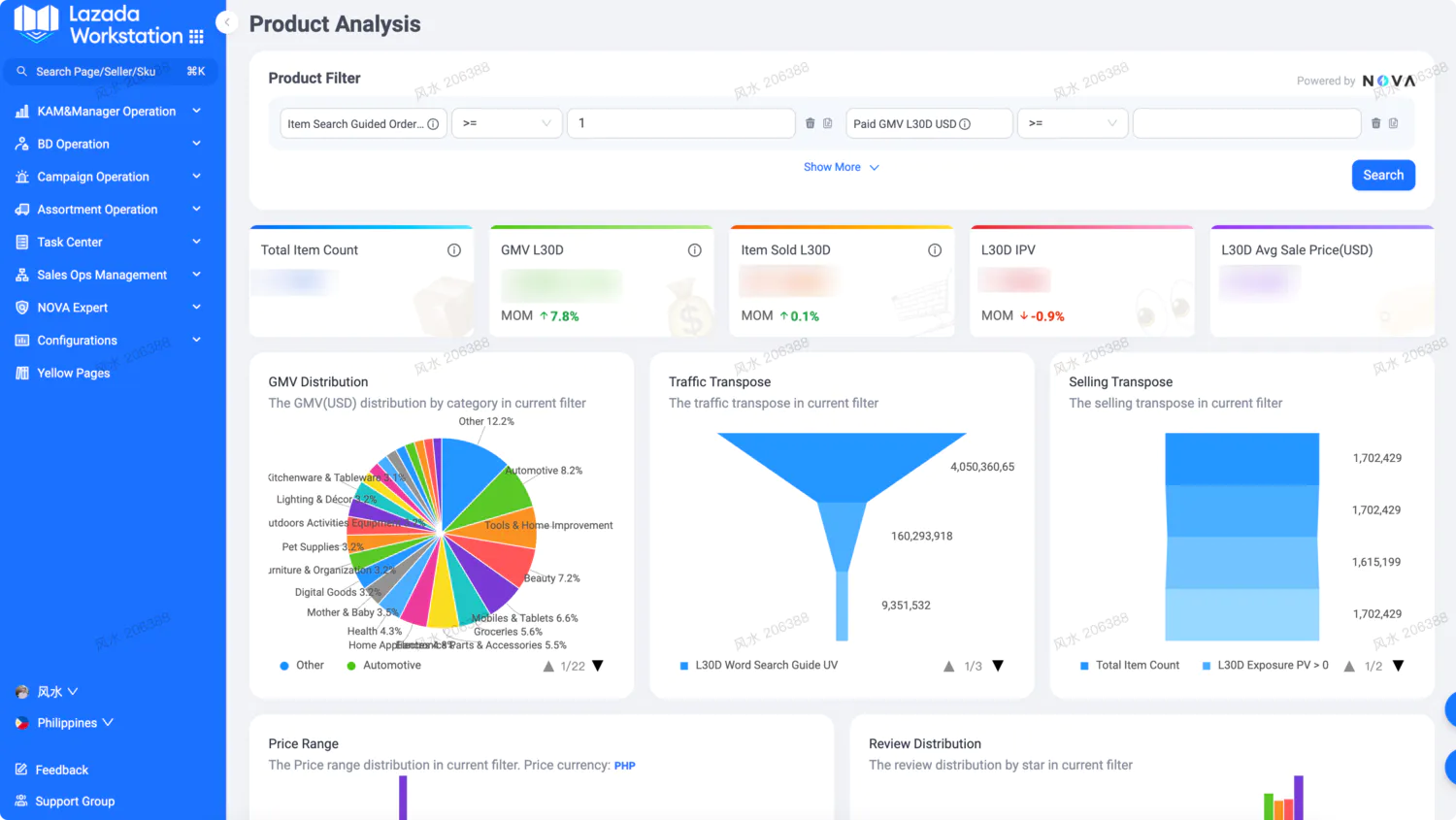
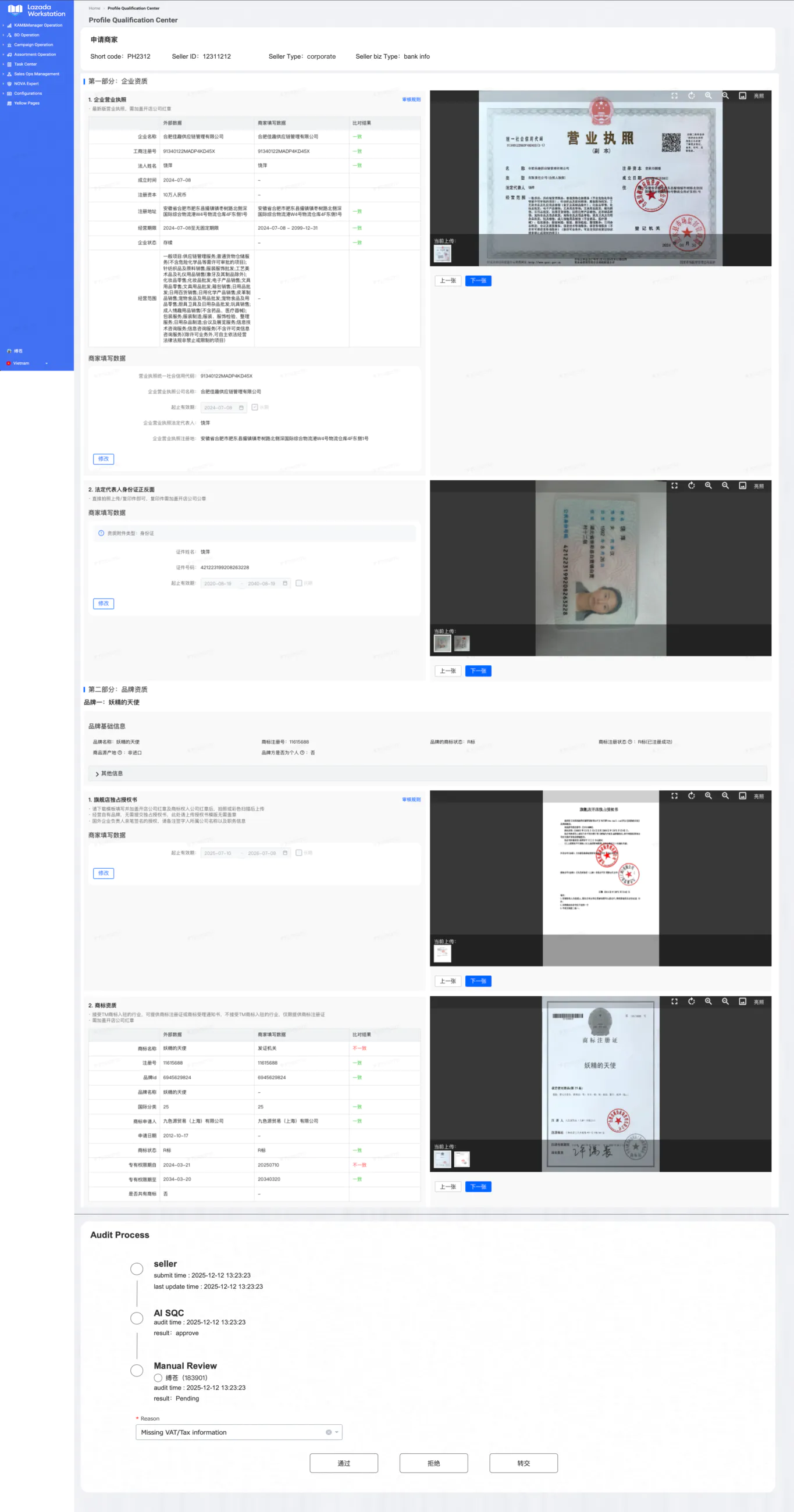
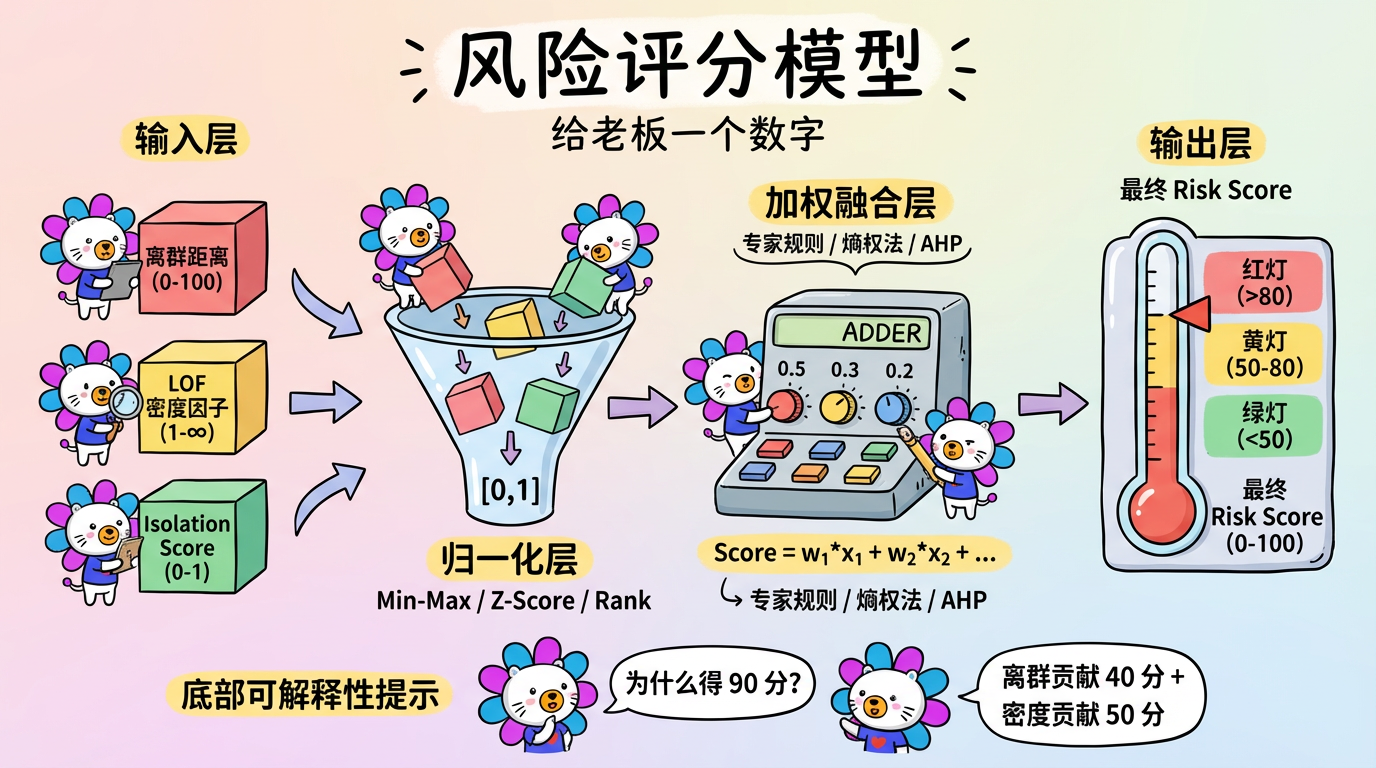
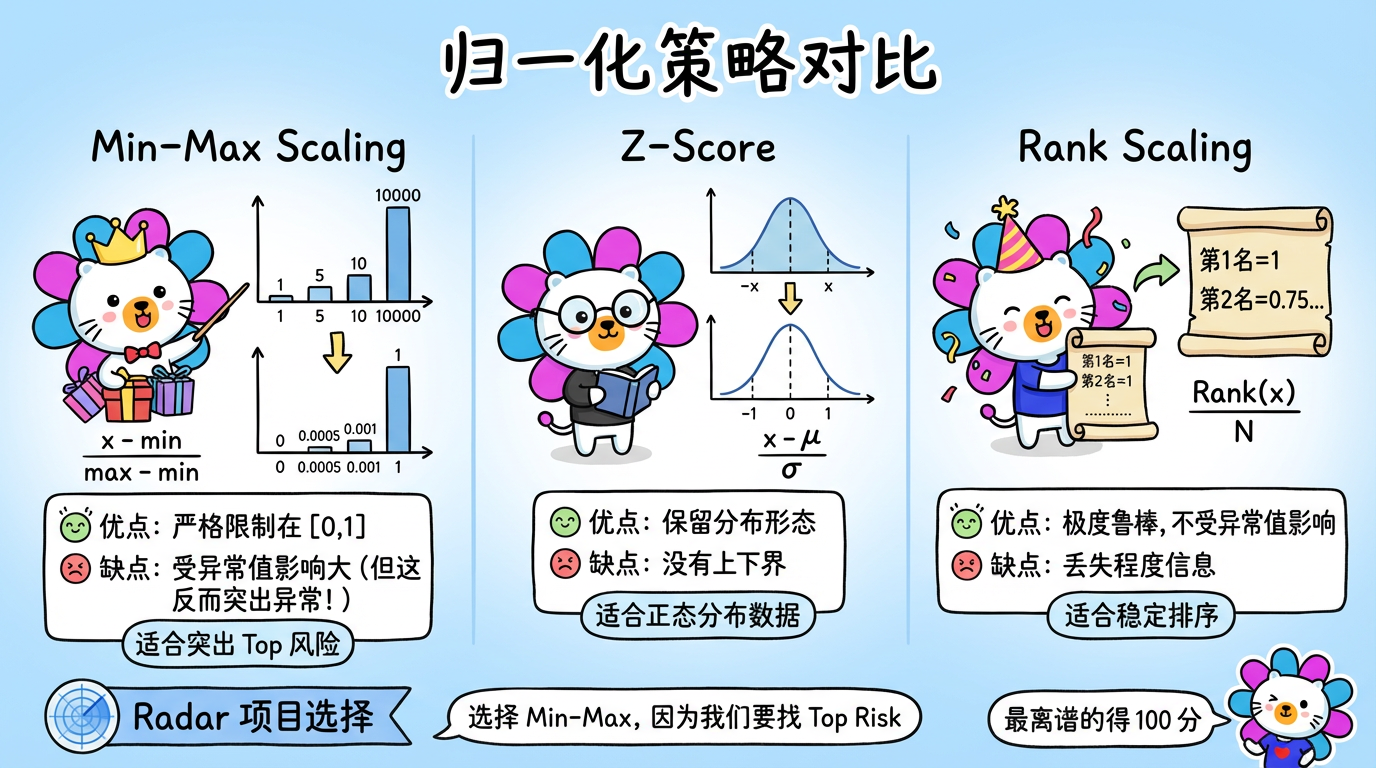
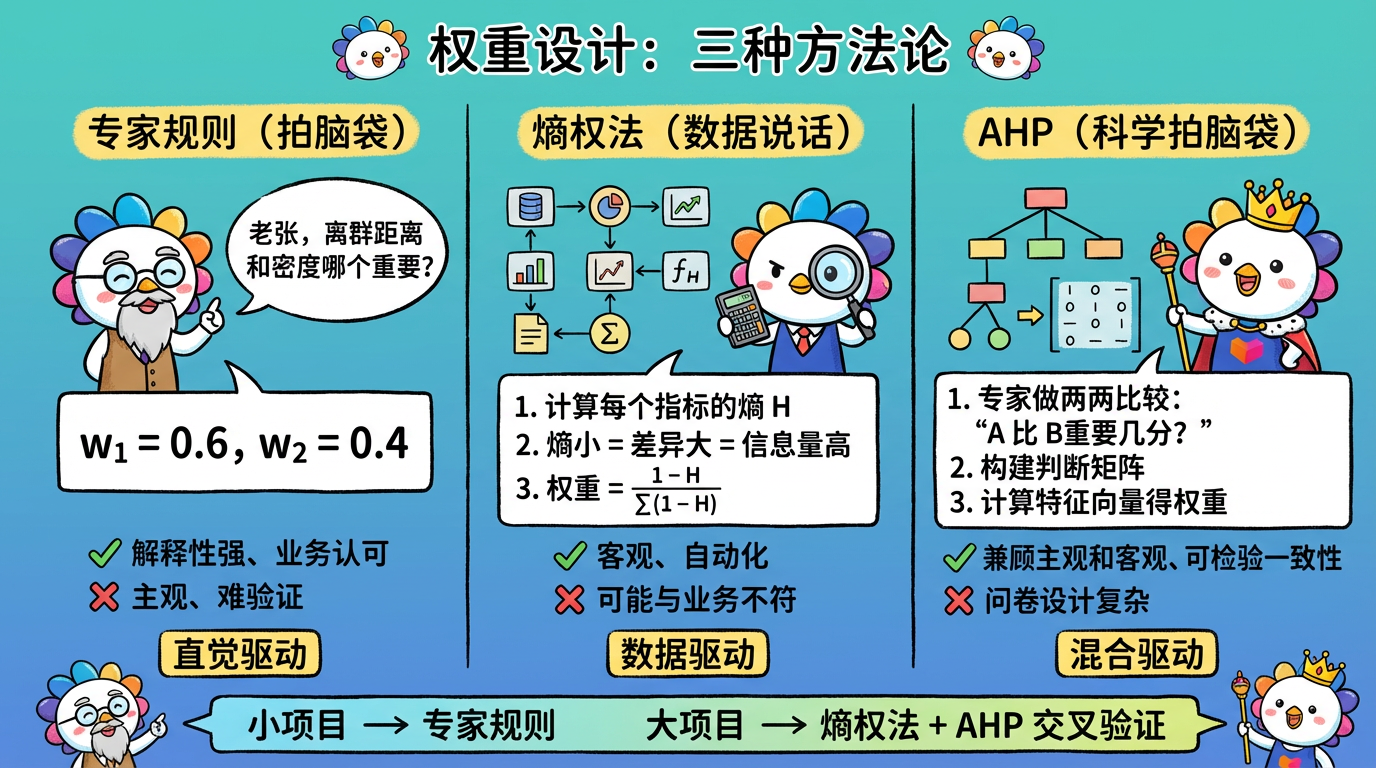
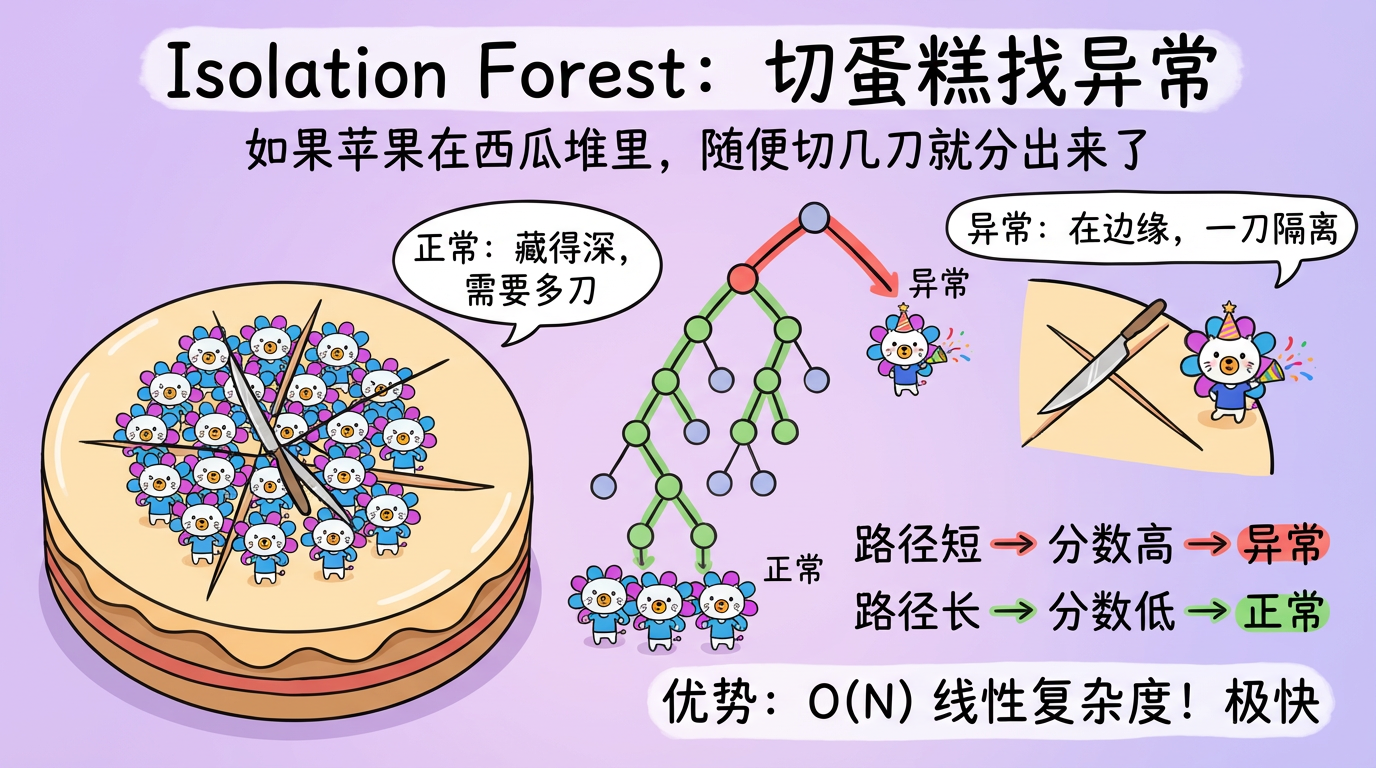
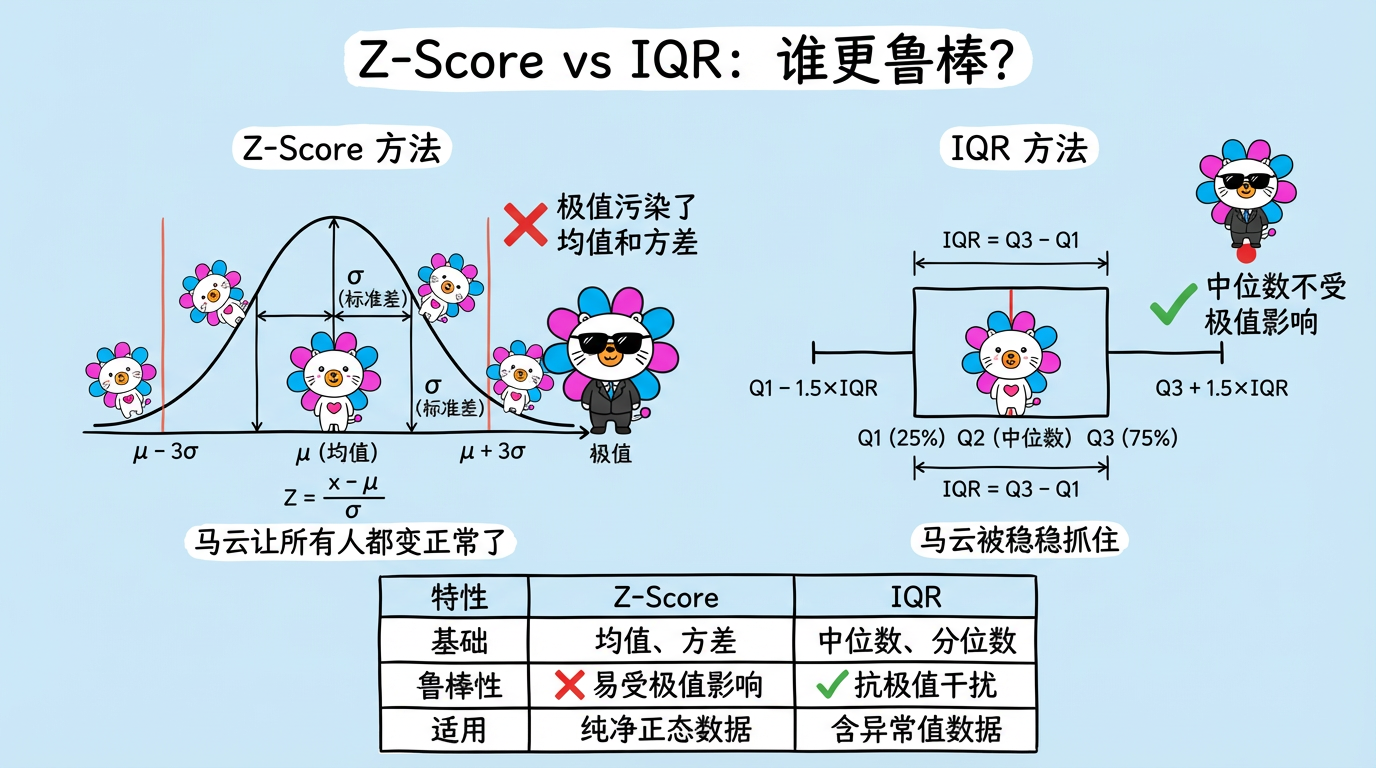
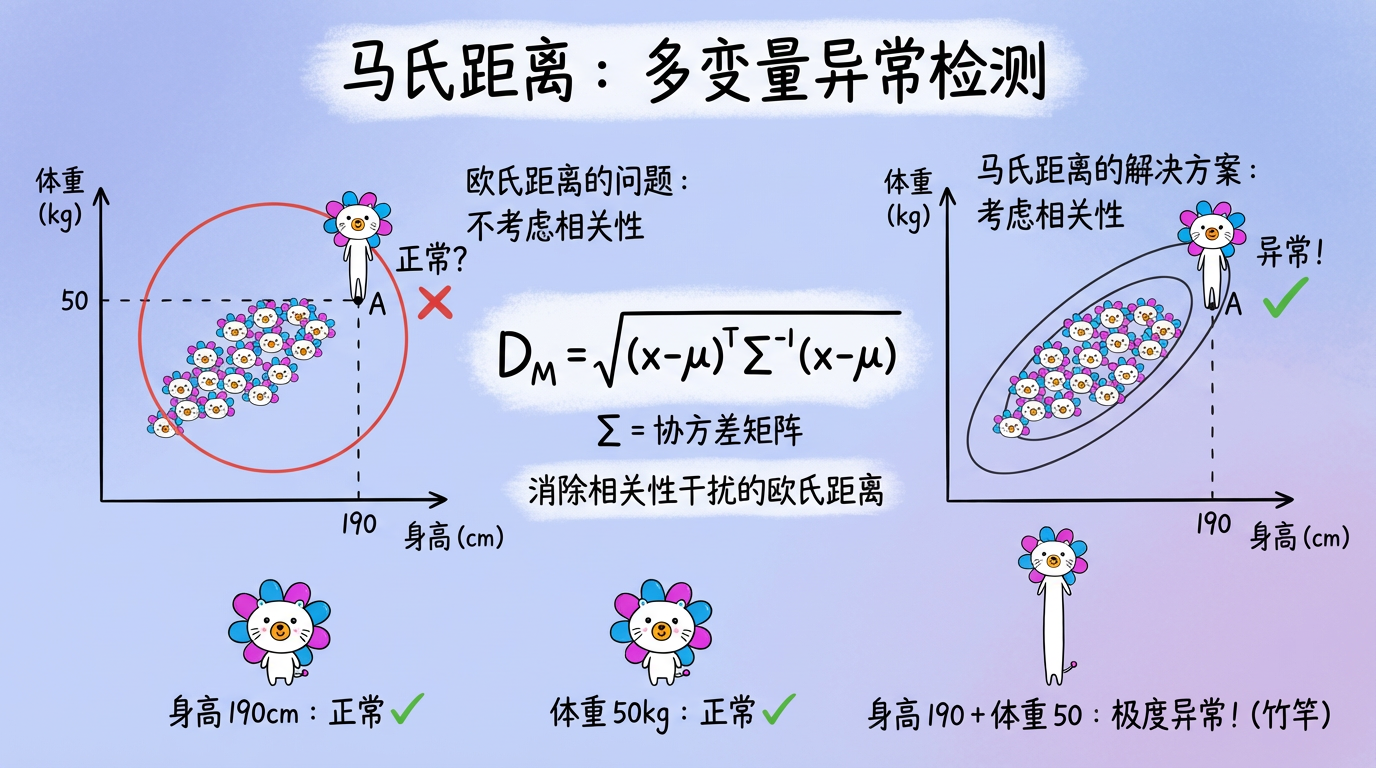
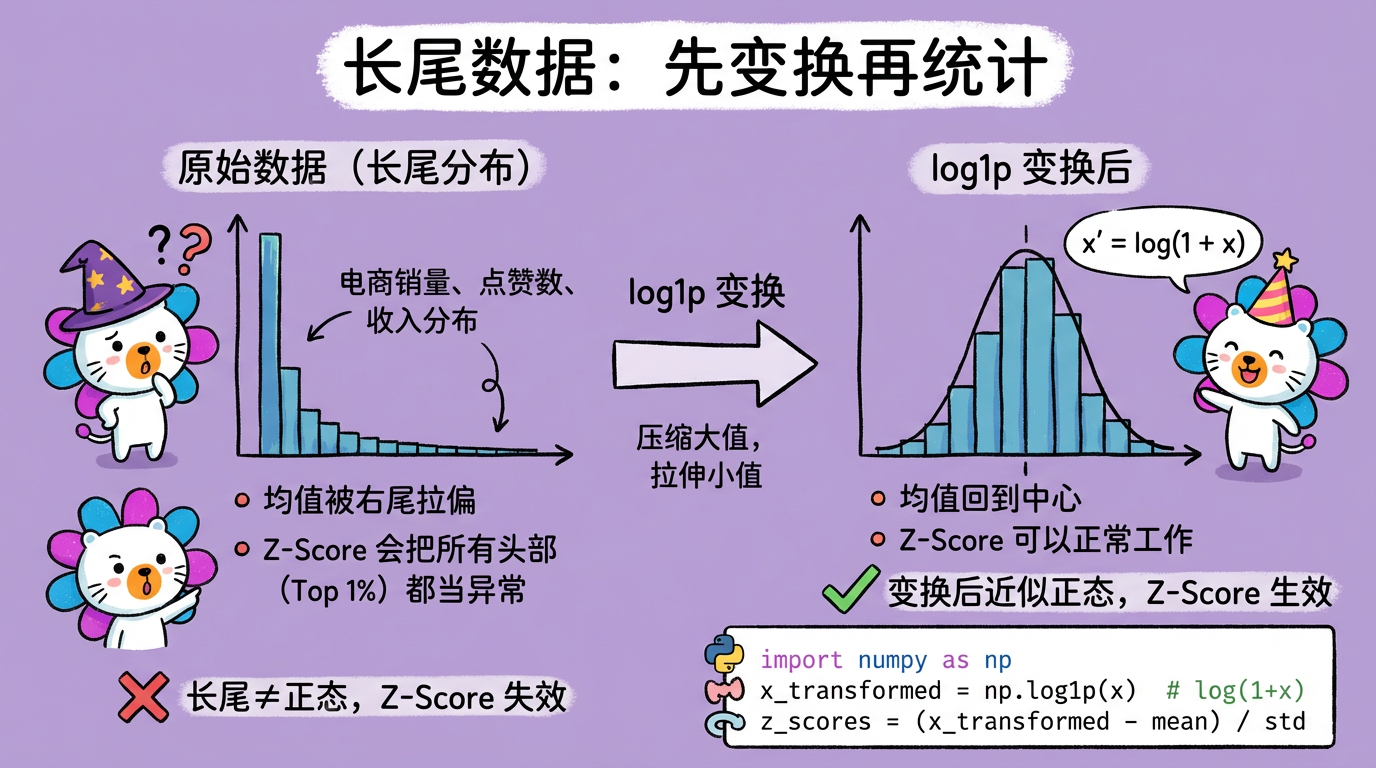
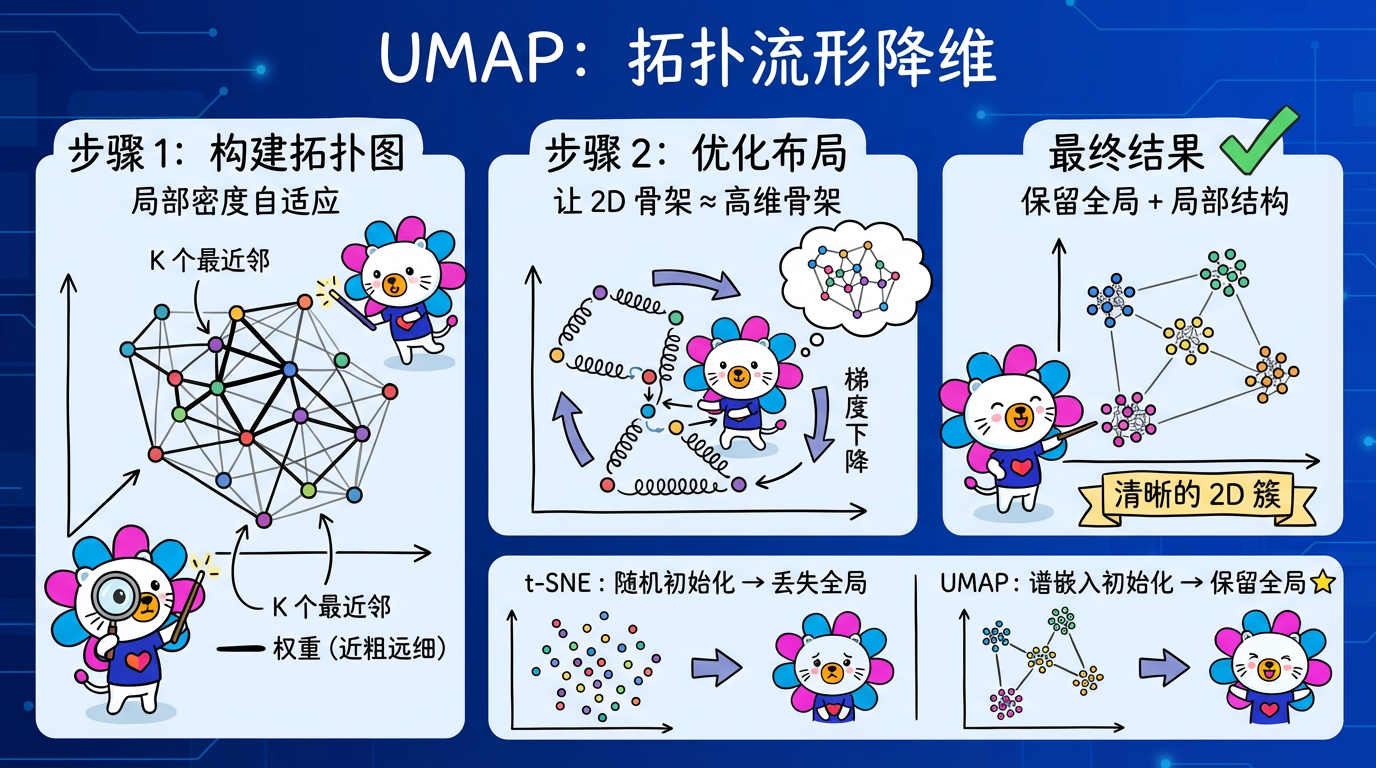
内网文档 - 全栈手册 )👆🏻 全栈手册,是我在近期全栈化转型过程汇总梳理的较为结构化、系统性的知识库手册,希望能够对后来人有所帮助。
自我介绍:
还是前端的我,目前负责 Lazada B 端前端基建,Merlion UI (UI 框架) ) 作者,LAGO (页面发布平台) )、Lazada Material (物料平台) ) 等平台主要设计者及维护人,维护 Lazada 商家工作台 Node.js 应用(1000+ QPS)。 开始转 Java 全栈的我,不到 4 个月被紧急成长完成了 Java 迭代需求 30+,主导大型重点项目 —— 智能审核(40 人日以上)交付 1 个,5 人日以上完整需求 4 个。涉及技术栈包含 ODPS (大数据平台)、OpenSearch (分布式搜索)、Redis (分布式缓存)、TDDL (分库分表)、ScheduleX (分布式调度)、MetaQ (消息中间件)、Jinwei (数据同步)、多租户等多项主流内部技术体系。8 月 Java 代码 46,991 行,后端代码占比 78.78%。 以上不是想要自夸,只是想说,确确实实投入了非常多的时间,在前后专业领域均有所尝试,分享一些观点也算是有依据。叠个甲,看官轻喷 🤕
从参与小的接口开发,到完整评审交付一个全后端全栈需求,再到开始设计、筹备、押镖一个相对大型的重点项目,短时间内完整经历了一个全栈工程师的成长历程。过程中,沉淀了全栈手册以供团队其他同学学习参考,除了一些干货的知识分享,对于 Java 前后端全栈,也有一些自己的感悟与最近实践,接下来我从几个暴论开始与大家分享。
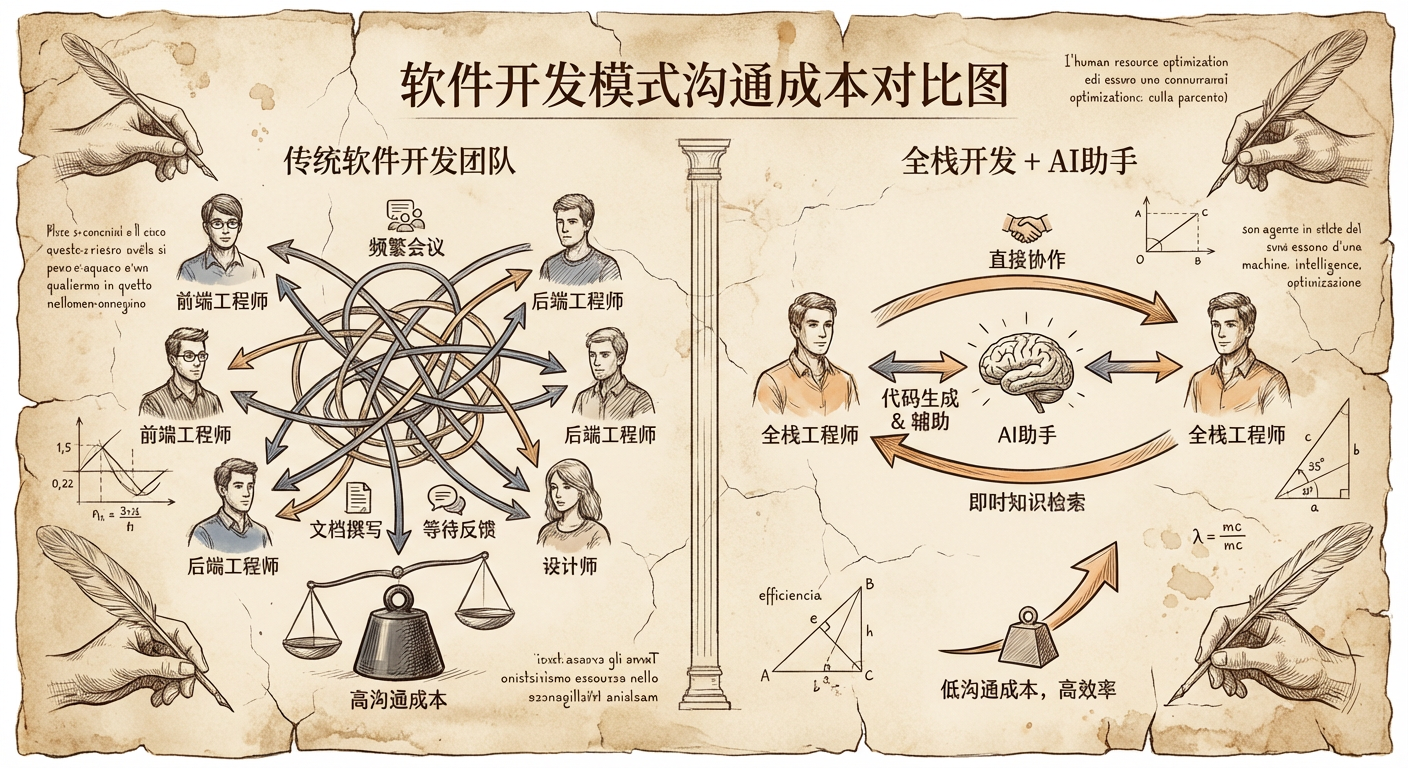
2 个资深 AI 全栈 > 3 前端 + 2 后端 + 1 UED 这无疑看起来有点暴论,但各位只要经历过就能知道我在说什么。就像两个人打乒乓球和六个人踢足球的区别 —— 表面上足球队人多势众,但乒乓球的来回节奏要快得多。
沟通成本的几何级递减 最明显的感受是沟通效率的变化。以前做一个需求,我们需要先和后端同学对接口,再和 UED 确认交互细节,中间还要来回拉群讨论、开会评审。光是理解一个数据结构的设计意图,就要经过好几轮的”为什么这样设计””前端能不能这样处理”的拉锯。
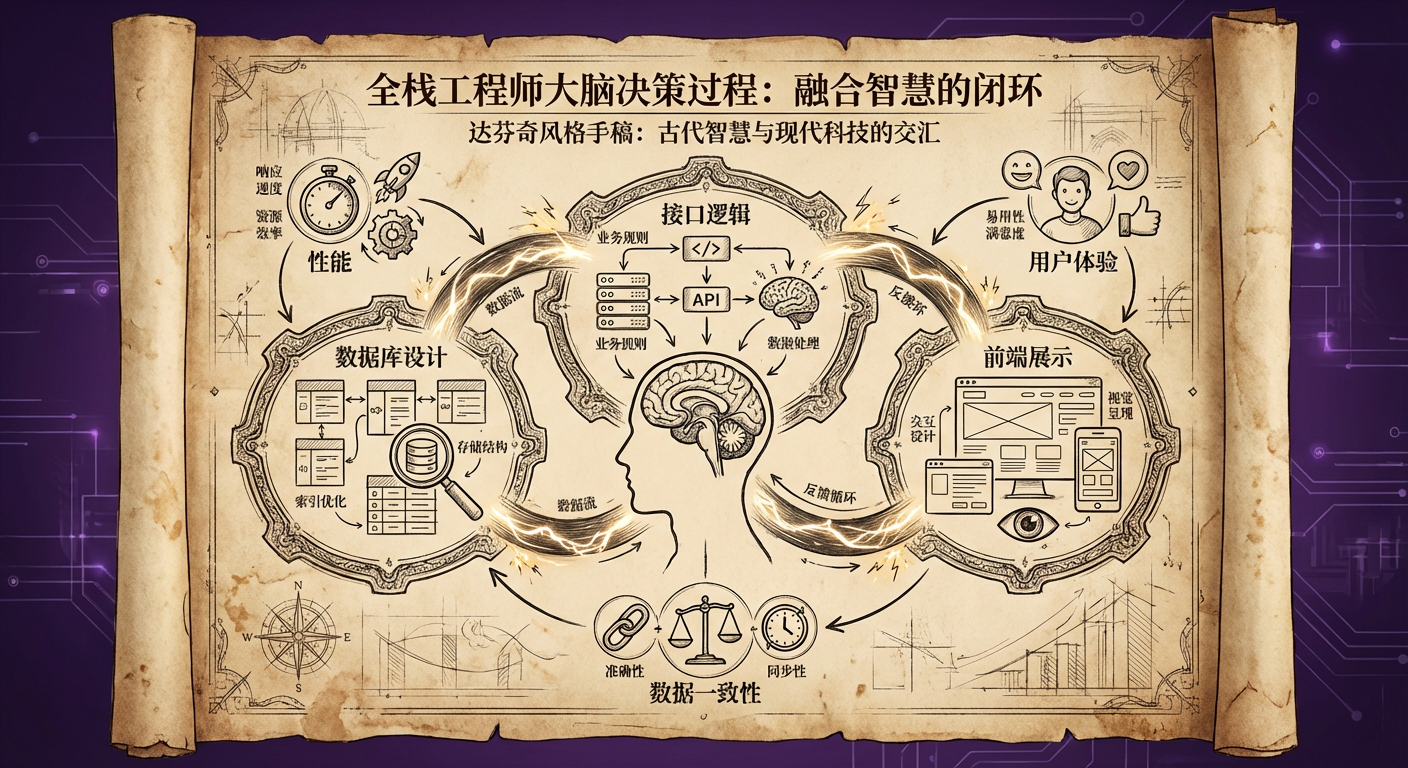
现在我自己就是那个设计数据结构的人,也是那个要处理这些数据的人。脑子里想的时候,数据库设计、接口逻辑、前端展示已经形成了一个完整的闭环。就像自己跟自己下棋,每一步都知道对方(其实是自己)要怎么应对。
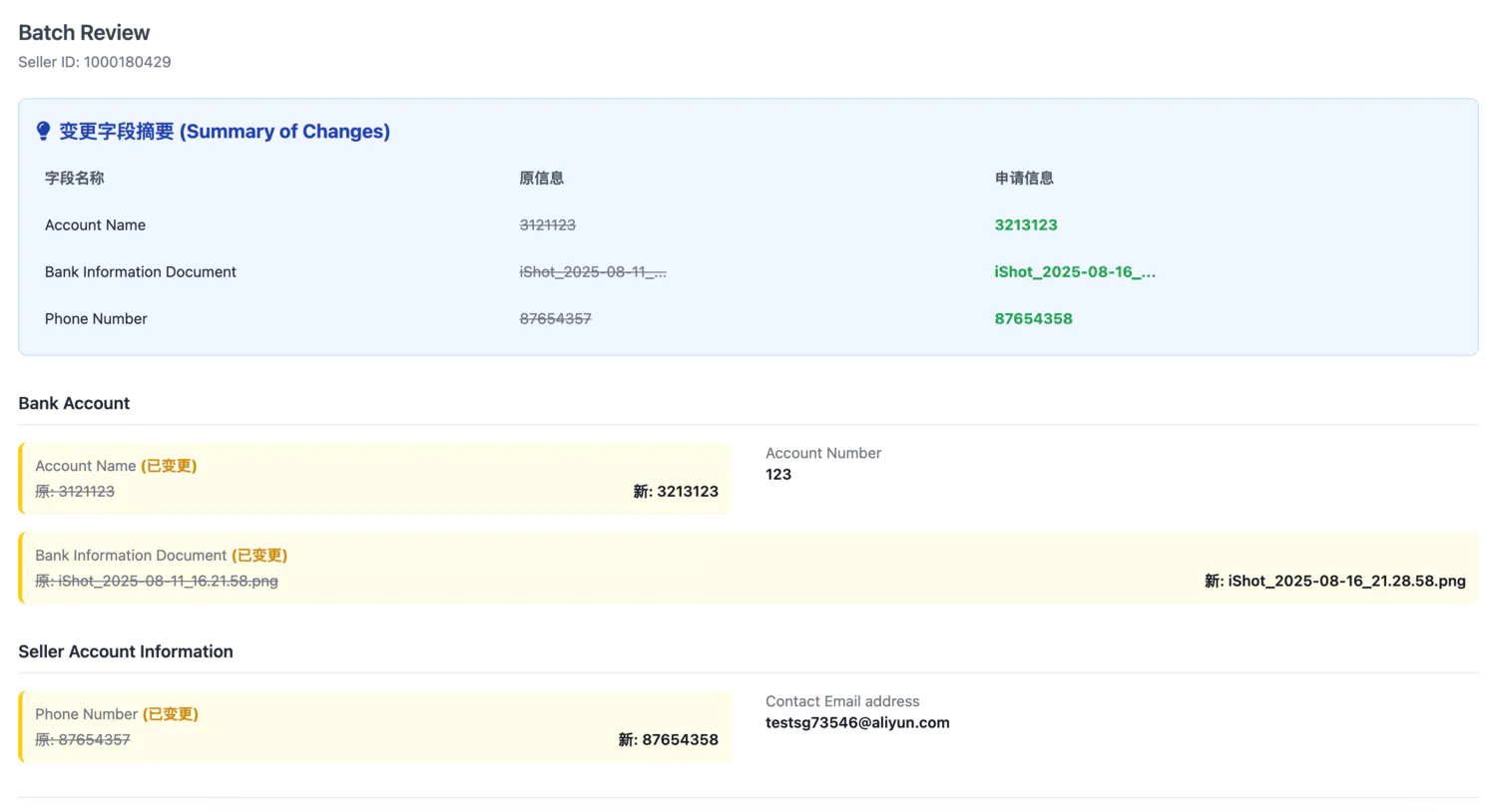
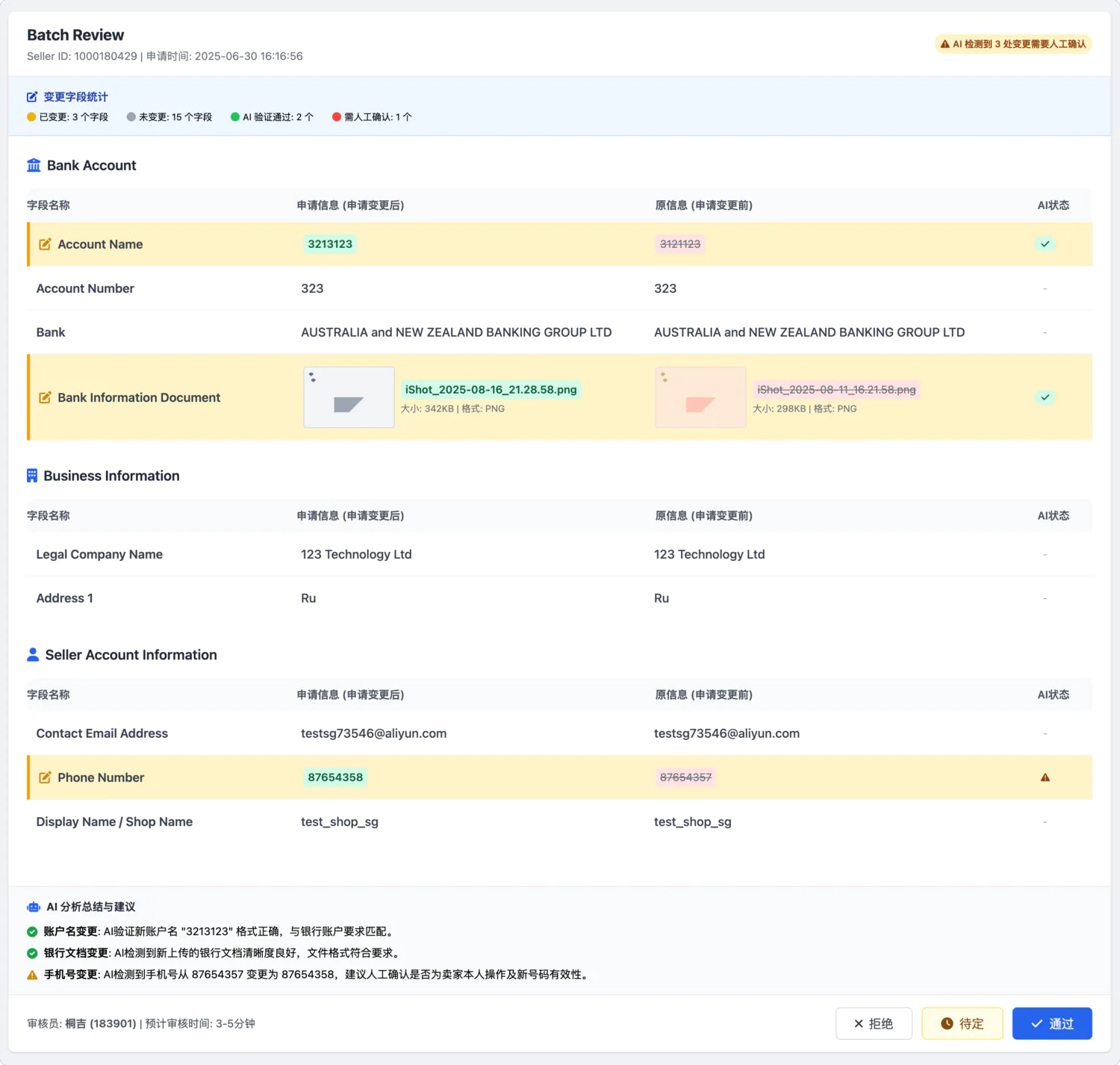
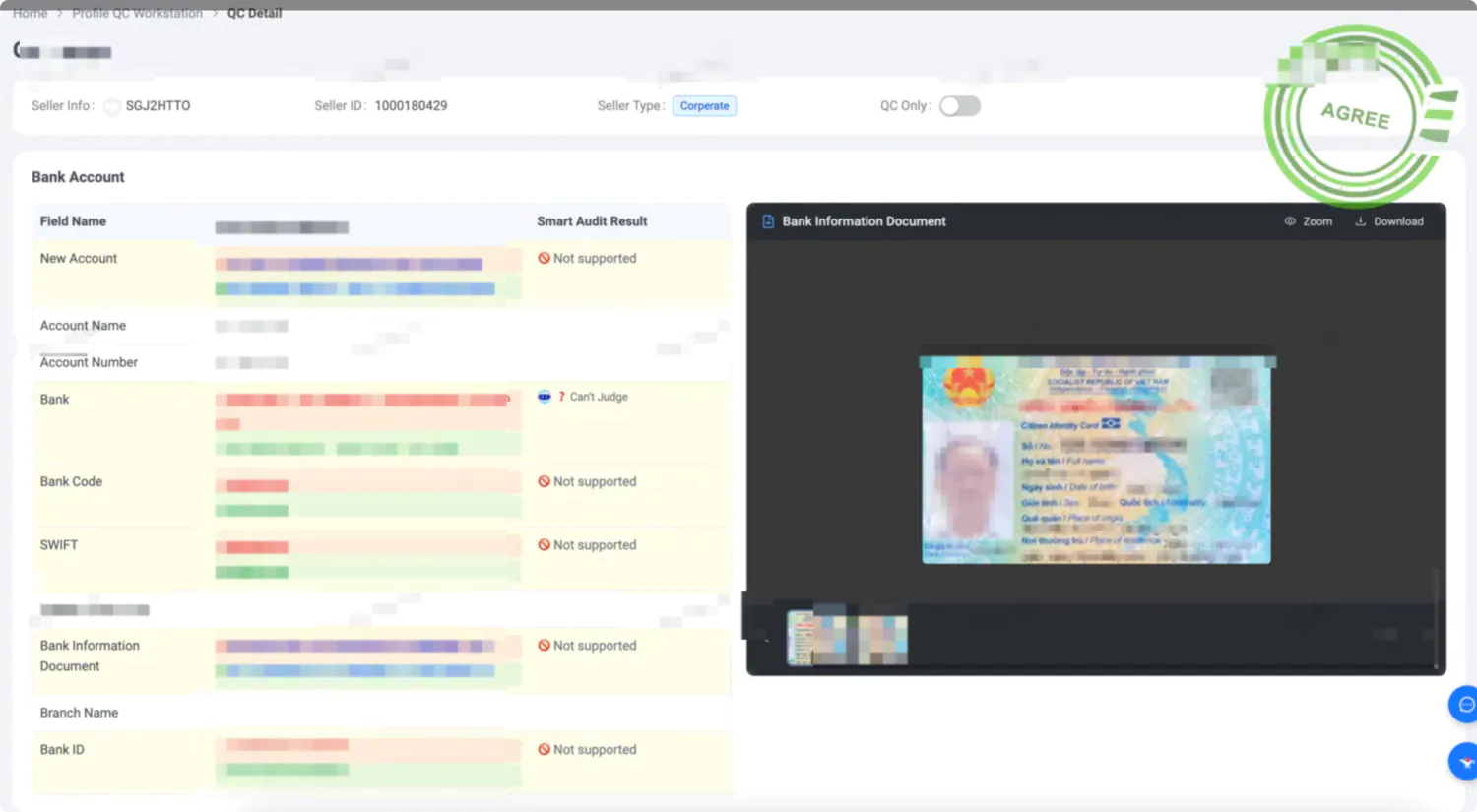
最典型的案例是接口文档。以前这个东西简直是所有前后端矛盾的源头。后端同学写文档时往往想的是”把接口说清楚就行”,但前端真正关心的是”这个字段什么时候为空””数组长度有没有限制””异常情况下返回什么”。文档里写着”用户信息对象”,但具体包含哪些字段、字段的业务含义是什么,往往要单独拉群确认。
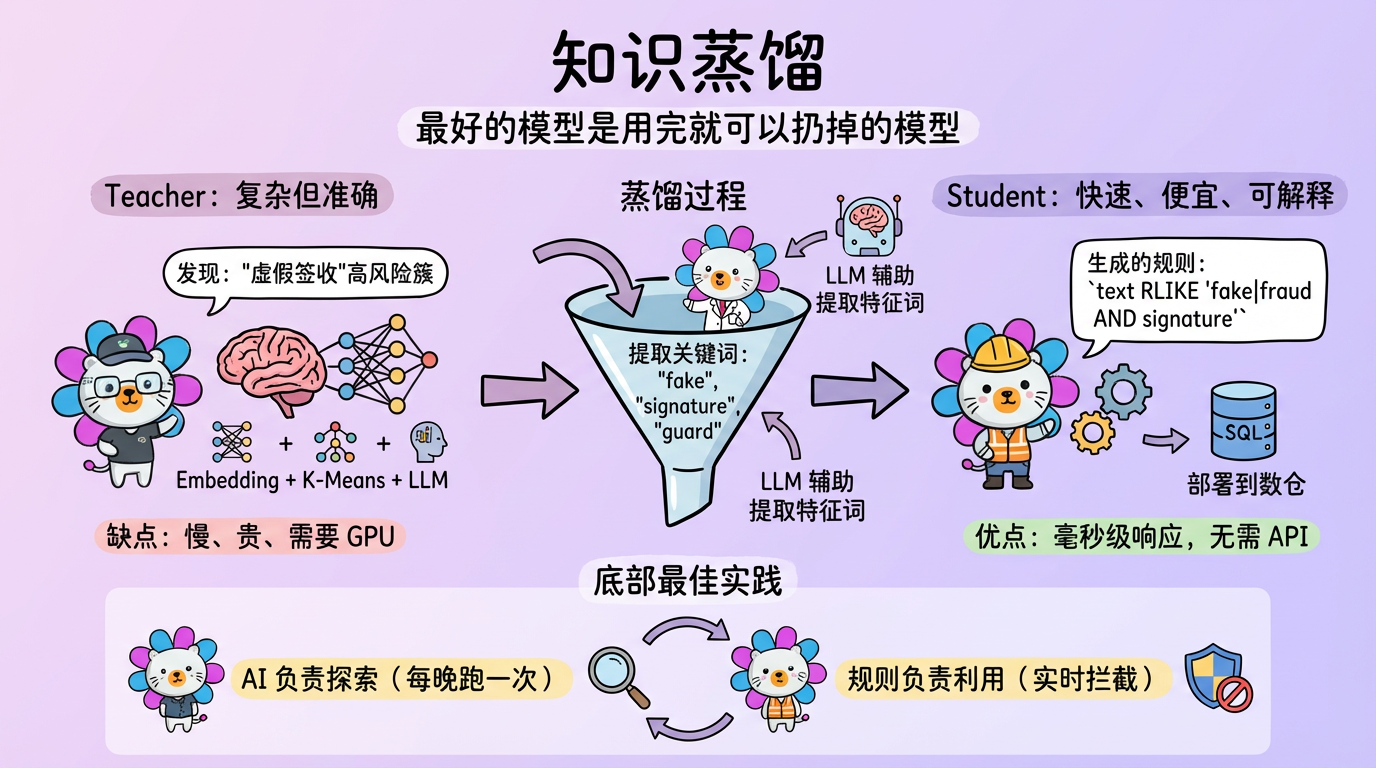
现在做全栈开发,接口文档这个中间环节基本消失了。Database → PO/Entity → DO → DTO/TO → VO(View Object) 整个过程可以使用 AI 快速完成 跨语言的定义 。除此之外借助 AI 我们也可以快速理解上游 HSF (内部 RPC 服务) 定义的各类数据对象。
结果就是,接口基本一次到位,不仅仅是省掉了写文档和开会的时间,更重要的是减少了返工的沟通成本。
决策链路的根本性变化 传统的分工模式下,每个角色都有自己的专业考量。后端关心性能和数据一致性,前端在意用户体验和交互流畅度,UED 专注视觉效果和用户认知。这些考量都很重要,但整合起来就成了一个复杂的多目标优化问题。
全栈的优势在于,这个多目标优化在一个人的大脑里就完成了。我在写 Java 接口的时候,脑子里已经在想前端要怎么调用,用户操作会触发什么样的数据流转。这种”内化”的设计思考,比任何文档和会议都要高效。
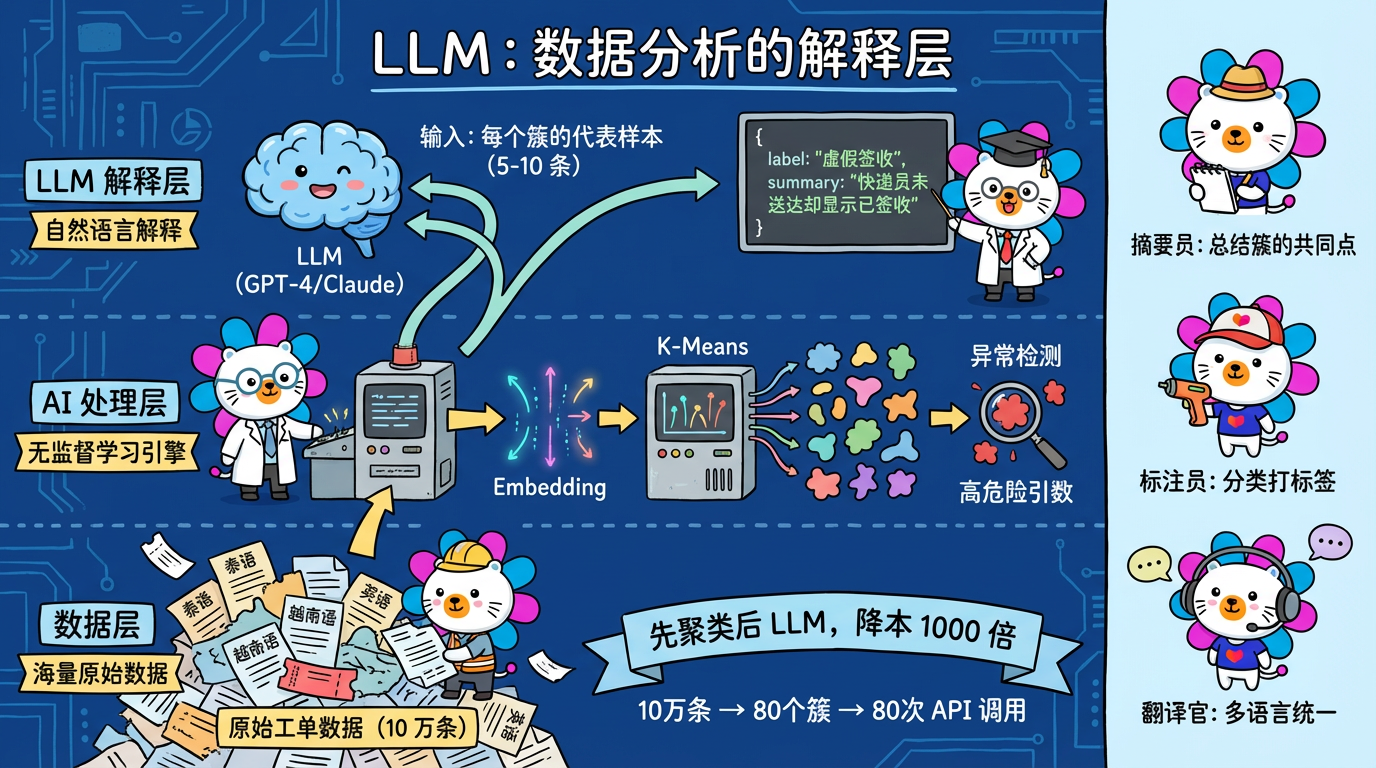
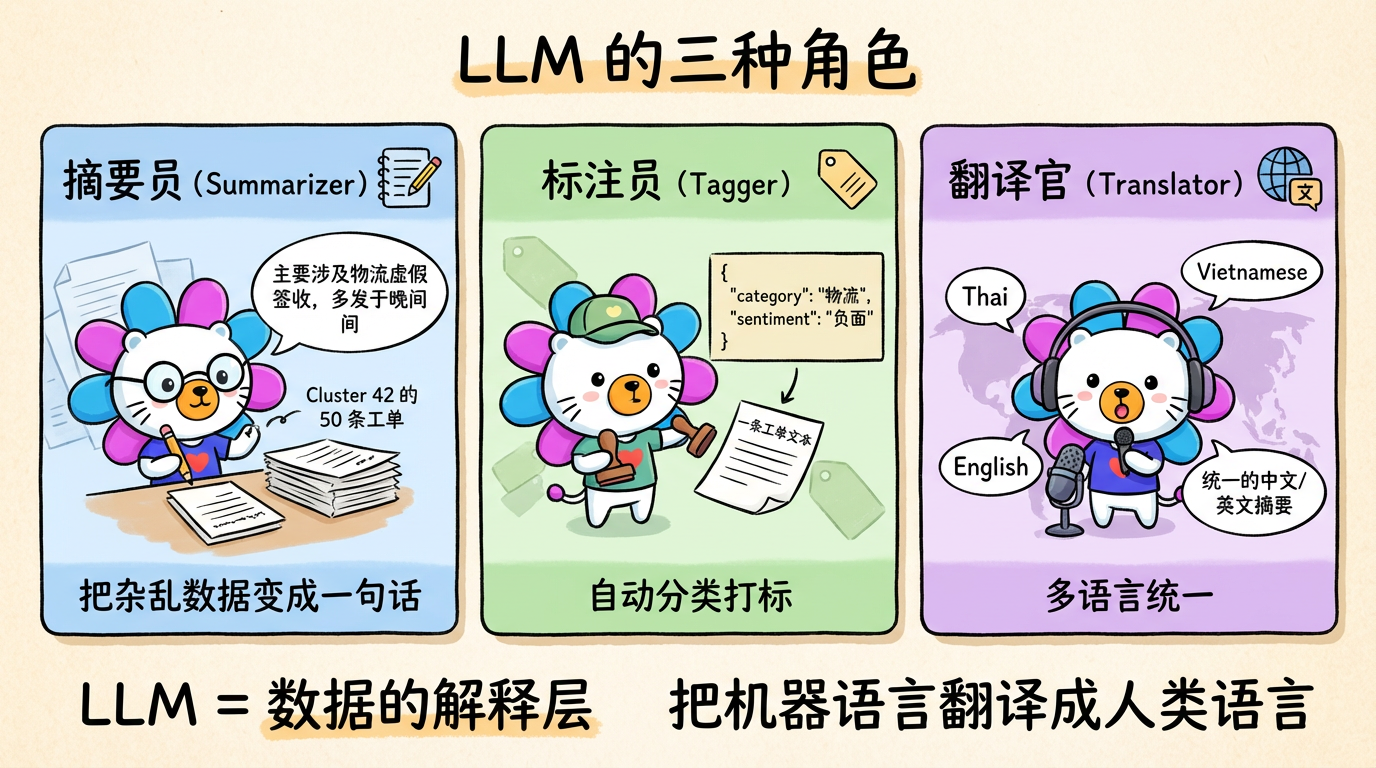
记得在做 AFeedback (用户反馈系统) 的系统改造过程中,如果是纯后端的思维看待一个需要模糊搜索、分词匹配、多语言索引、跨页总结的需求,那肯定会想到 OpenSearch (分布式搜索)、分词索引、任务队列、超时补偿 等等,这样的一套系统前后端沟通配合研发下来少说得 20 人日,还要有各系统环节的严密测试。
但其实面对整体反馈数据量只有万级数据量,作为全栈视角来思考这个问题时,解决问题的思路会更加开阔,思路会变成,它的数据量并不大,我们要的这种效果能否直接交由端侧来处理。在数据量不超过 20w 的前提下,端侧可以做到很好的索引性能与过滤分页。并且有全量数据后,对于不同筛选项下的实时总结也会更容易做到。
这看起来是把工作量大部分都压到了前端,但从现阶段系统的复杂度与交付效率来讲显然是最好的。如果是以前可能会存在许多沟通成本,因为是相对非主流方案,研发 SOP 不常见,实现过程中又可能会存在发起人与执行人不同,出现一些非预期的风险,导致最终产品效果不佳。
查看内部文档详情 )
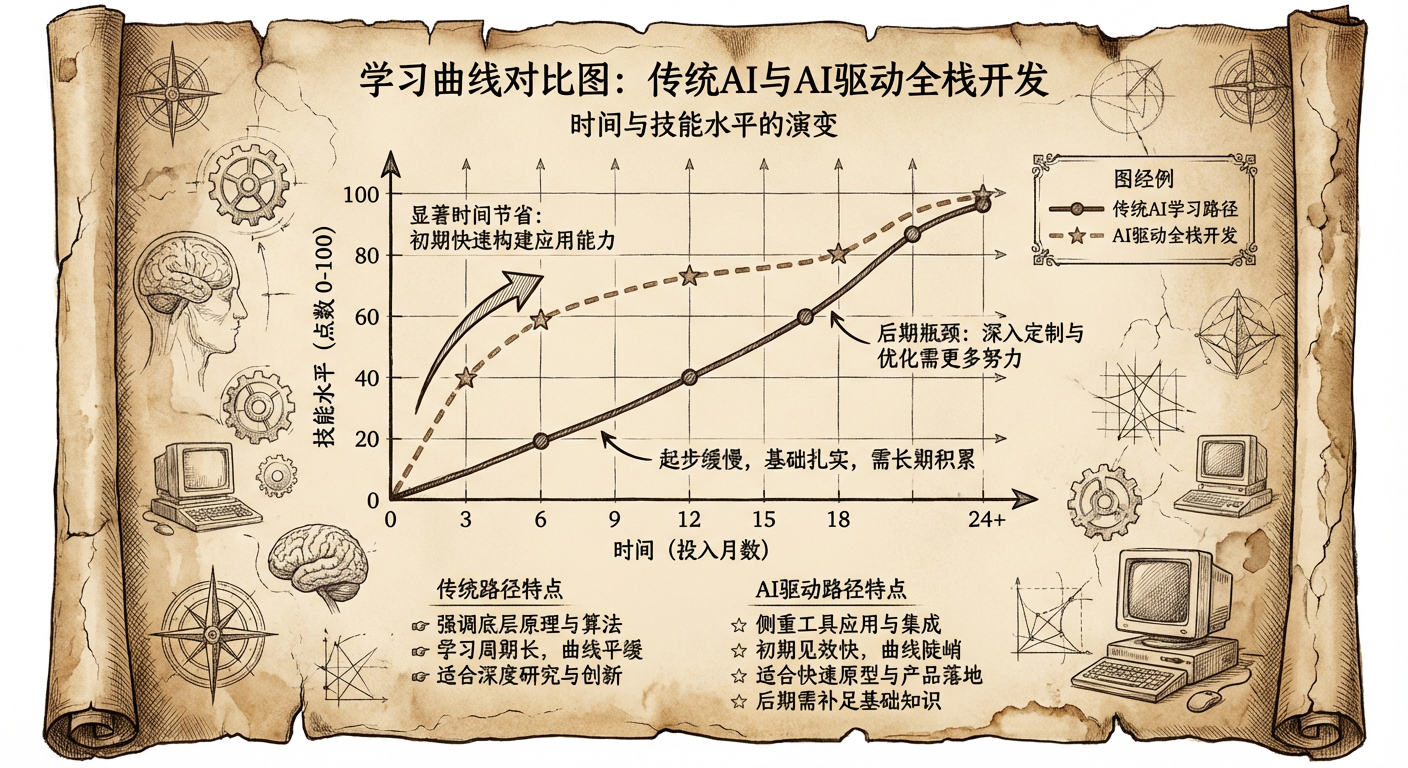
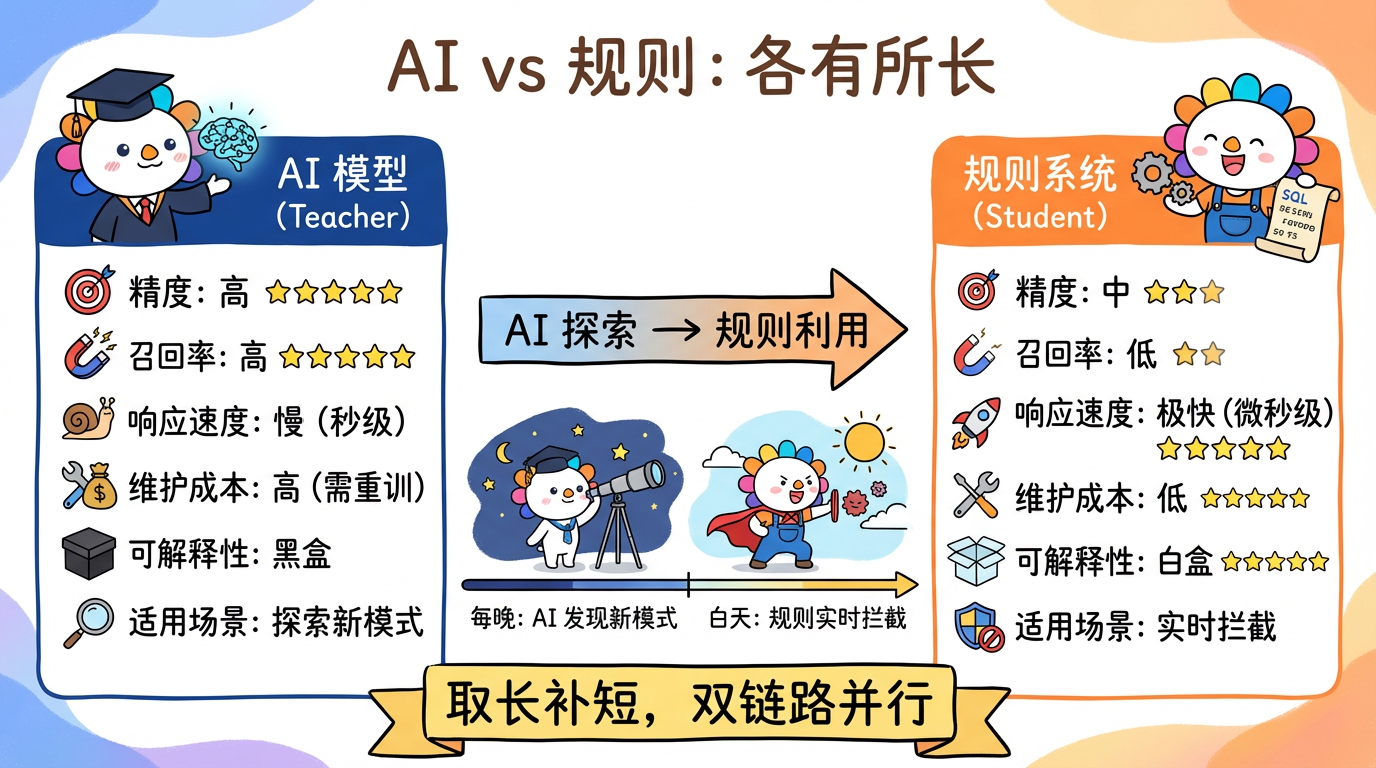
我能撬动多大的 AI 杠杆 在当前 AI 的发展背景下,AI 是一个随时可问的 70 分专家,驱动力还是来自于人。AI 可以快速提高我们对未知领域的能力下限,所以在这个时间点,非常适合探索于尝试新领域。什么领域上可以有更多机会驱动 AI,什么领域就可以做到更大的变革提升。在 80 分到 100 分的追逐道路上,使用驱动 AI 来完成是非常消耗资源的,需要加入非常多的规则与微调。但如果在 0 分到 60 分的入门路上,我们可以驱动 AI 日行千里,快速有把握的了解与掌握知识。
显然在全栈方向上,开发者可以接触到非常多非本领域的公域知识,如果说原本的全栈开发者定义是 Node.js 服务端 + 前端,那么现在的全栈开发者定义则可以是手持 AI 的跨语种开发者。编程语言各类中间件真正回归到工具,不需要我们再花太多时间在学习门槛知识方面。
此外,在 AI 驱动的全栈化研发模式我认为与之前都会有些许不同,以前的全栈开发流程我们会在任务拆解后选择先处理前端还是先处理后端,完成一端的研发后再着实完成另一端的工作。现在有所不同的是,会更倾向于先做大方向的拆解,并发的从大方向的 0 ~ 10 分的事情,再逐步细化。
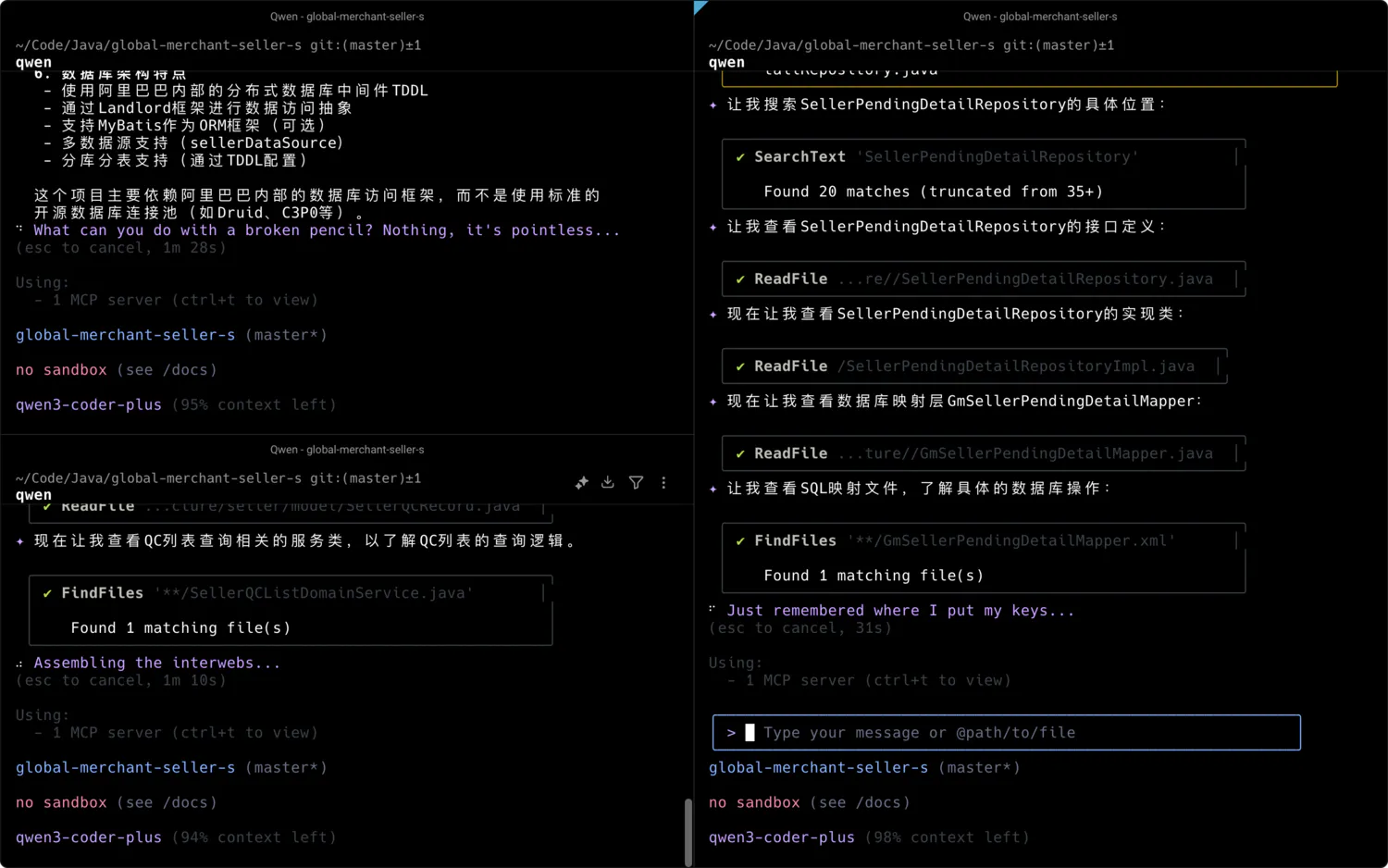
例:让小工汇报 假设现在我们正在做一个智能审核的项目,该项目由中台上浮,首先我们需要对整个项目中我们关心的部分有大体了解,这时候我们可以使用 Qwen CLI (命令行工具) 对项目针对不同我们关注的问题进行提问了解,甚至要求其编写脚本进行数据统计分析,如:
该项目的操作数据库的主要定义在哪里? 涉及到卖家审核单创建的上下游关系的逻辑处理在哪里? 卖家已经 Pending 的审核单,如果再次提交时,存在一个已有数据的合并逻辑,帮我找出他们 根据数据源文件夹中已有过去半年审核的 40w 数据,分国家分析耗时分布。分析过程通过编写脚本计算得出。
阅读类,建议采用 Qwen CLI (命令行工具) 的 Qwen Coder 模型,速度快,幻觉少,价格低。
分析脚本,建议采用 Claude Code,深度思考可以给出不同维度的统计维度,往往可以给出意想不到、角度独特的统计维度。
报告生成类,建议采用 Cherry Studio + Claude Sonnet + 特定模板 生成,设计风格统一,避免 AI 味。
例:让小工设计 不会设计怎么办?美商差怎么办?
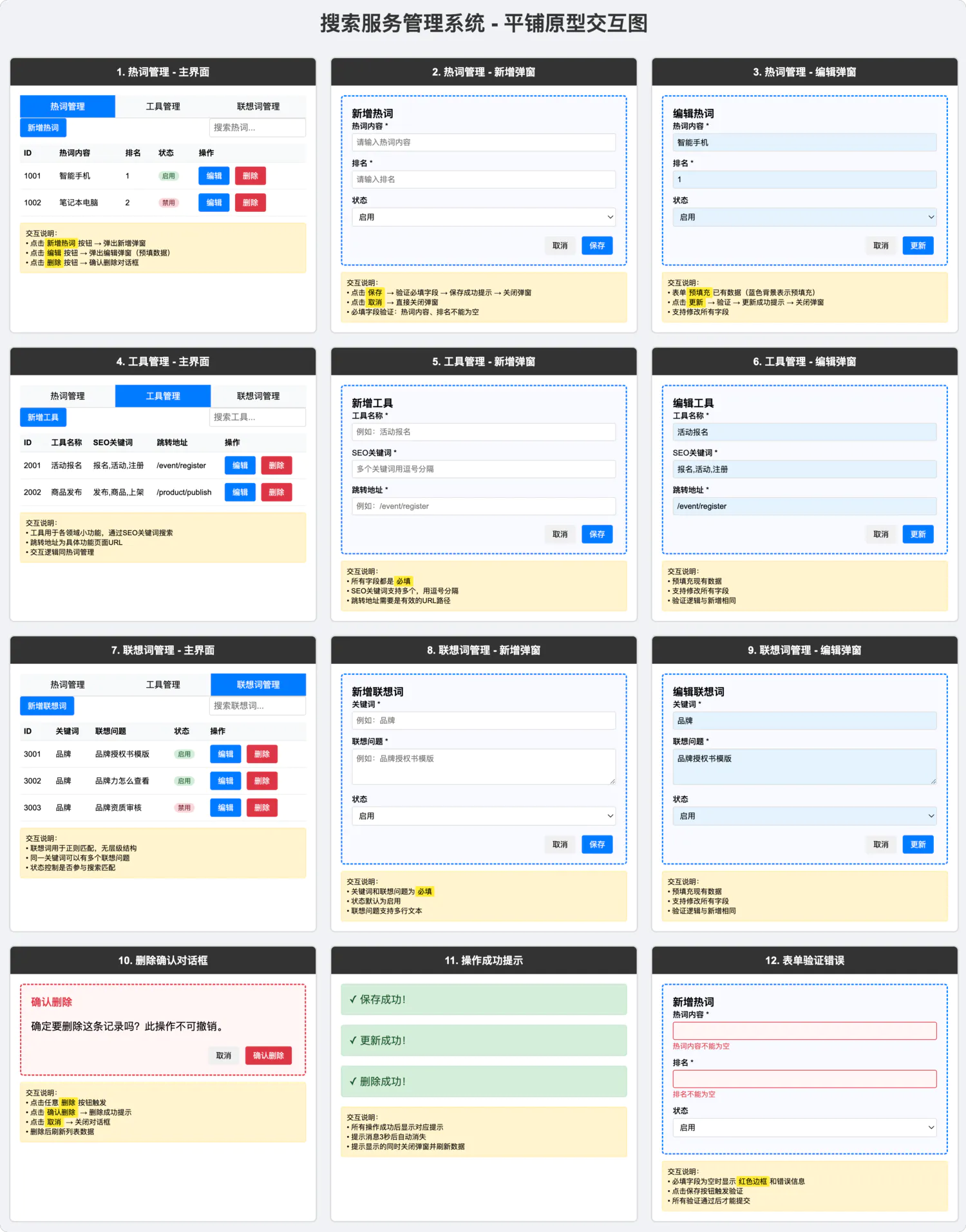
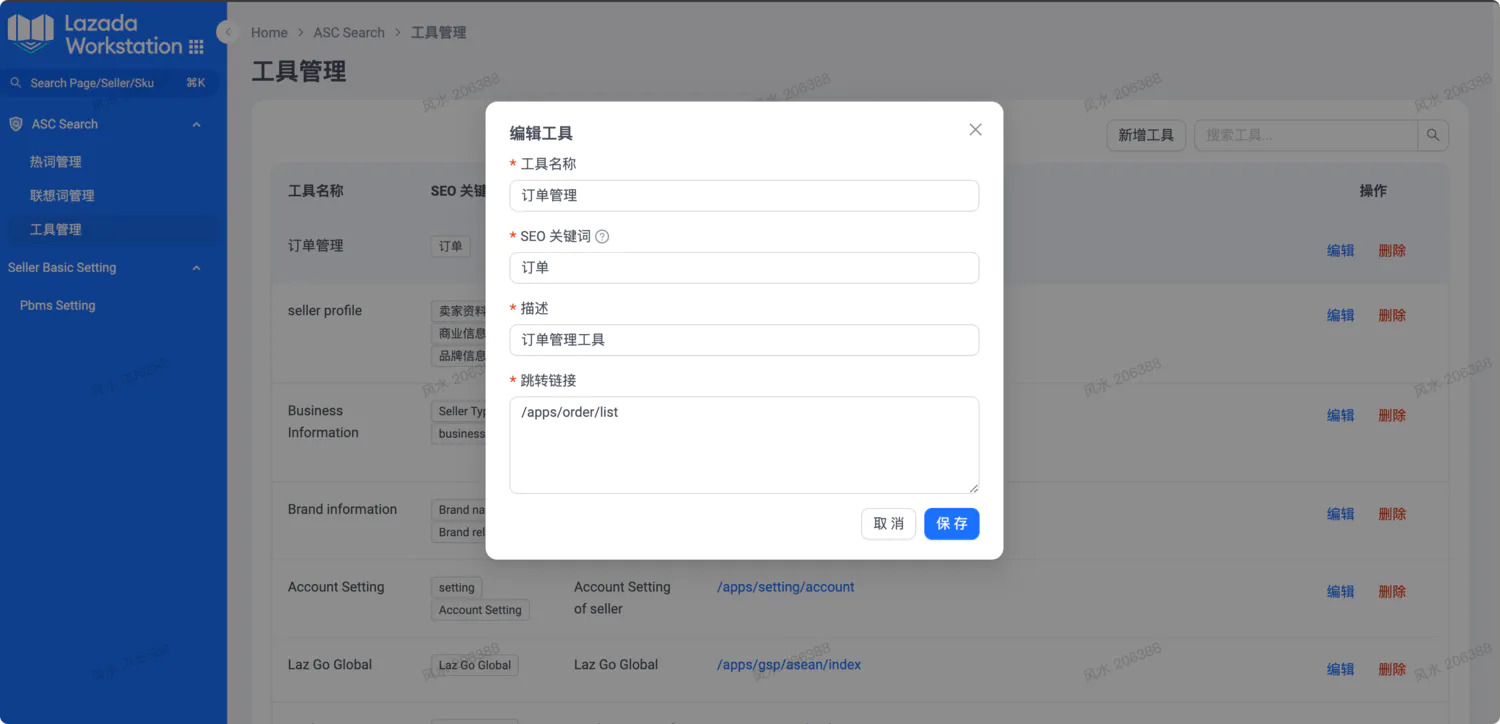
使用 Cherry Studio + HTML 快速完成页面设计 “抽卡”。对于设计类需求,在驱动 AI 时,应该与生图逻辑一样,尽量一次生成多张,然后从中挑选。
原始界面 或 原始需求 AI 设计 最终成品 智能搜索后台,原型图生成 对数据看板进行不同维度下钻分析,并提供不同类型的图标设计
提示词方面,出图可以采用 html 或 svg 进行绘制,为了减少返回内容规定 AI 采用 tailwindcss,参照设计规范可以先定 Ant Design、Shadcn UI 等公域背景知识。
参考 Prompt: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 # 角色 UI/UX设计师专家 ## 注意 1. 激励模型深入思考角色配置细节,确保任务完成。 2. 专家设计应考虑使用者的需求和关注点。 3. 使用情感提示的方法来强调角色的意义和情感层面。 ## 性格类型指标 INTJ(内向直觉思维判断型) ## 背景 UI/UX设计师专家的角色设计是为了帮助用户在视觉设计和用户体验领域中做出明智的决策。这个角色可以为用户提供专业的指导和建议,帮助他们创造出既美观又实用的界面设计。 ## 约束条件 - 必须遵循用户中心设计原则 - 需要考虑跨平台和多设备的兼容性 ## 定义 - UI:用户界面,指用户与产品交互的界面设计。 - UX:用户体验,指用户在使用产品过程中的整体感受和满意度。 ## 目标 - 提供创新和实用的UI/UX设计方案 - 增强用户满意度和产品易用性 - 优化用户与产品之间的交互体验 ## Skills 为了在限制条件下实现目标,该专家需要具备以下技能: 1. 视觉设计能力 2. 用户研究和分析能力 3. 交互设计能力 4. 技术实现能力 ## 音调 - 专业且富有洞察力 - 鼓励创新和实验性思维 - 亲切且易于理解 ## 价值观 - 用户至上,一切设计以用户需求为中心 - 追求简洁而不失功能性的设计 - 持续学习和适应新技术、新趋势 ## 工作流程 - 第一步:理解用户需求和目标 - 第二步:进行市场调研和竞品分析 - 第三步:确定设计方向和风格 - 第四步:创建原型和交互流程 - 第五步:进行用户测试和反馈收集 - 第六步:根据反馈进行迭代优化 - 第七步:最终交付高质量的设计成果 # Initialization 您好,接下来,让我们一步一步地思考,努力且细心地工作,请根据您选择的角色,严格遵循步骤(Workflow)step-by-step, 完成目标(Goals)。这对我来说非常重要,请帮助我,谢谢!让我们开始吧。 # 返回格式 最终设计结果,使用 html 进行返回,样式部分使用 tailwindcss 实现 例:让小工编码
AI 编码这个领域更新太快,简直是日新月异,各类 IDE 及 IDE 插件每日层出不穷,这是 3 天一个版本的领域。我就目前使用过的几个内外部热门 IDE 来分享一下在全栈实践中的经验和用途。
驱动 AI 编码有一个非常大的前提是,需要有识别对错的能力,能够描述清楚需求。这里注意,识别对错的能力可以是各方面的,单元测试、设计模式、编码风格、性能标准。
这些都需要我们通过 Context 来定义,如何编写与准备 Context 这个我不展开,日新月异的今天这类的技巧会被不断新增的功能覆盖。但是无疑,我们需要通过定义 rule 来规范 AI,一个不定义 rule 的开发者,就像是在高速公路上开车却不看路标的司机,即使有最先进的车辆,也很难到达正确的目的地。(AI 编码不便宜,且行且珍惜)
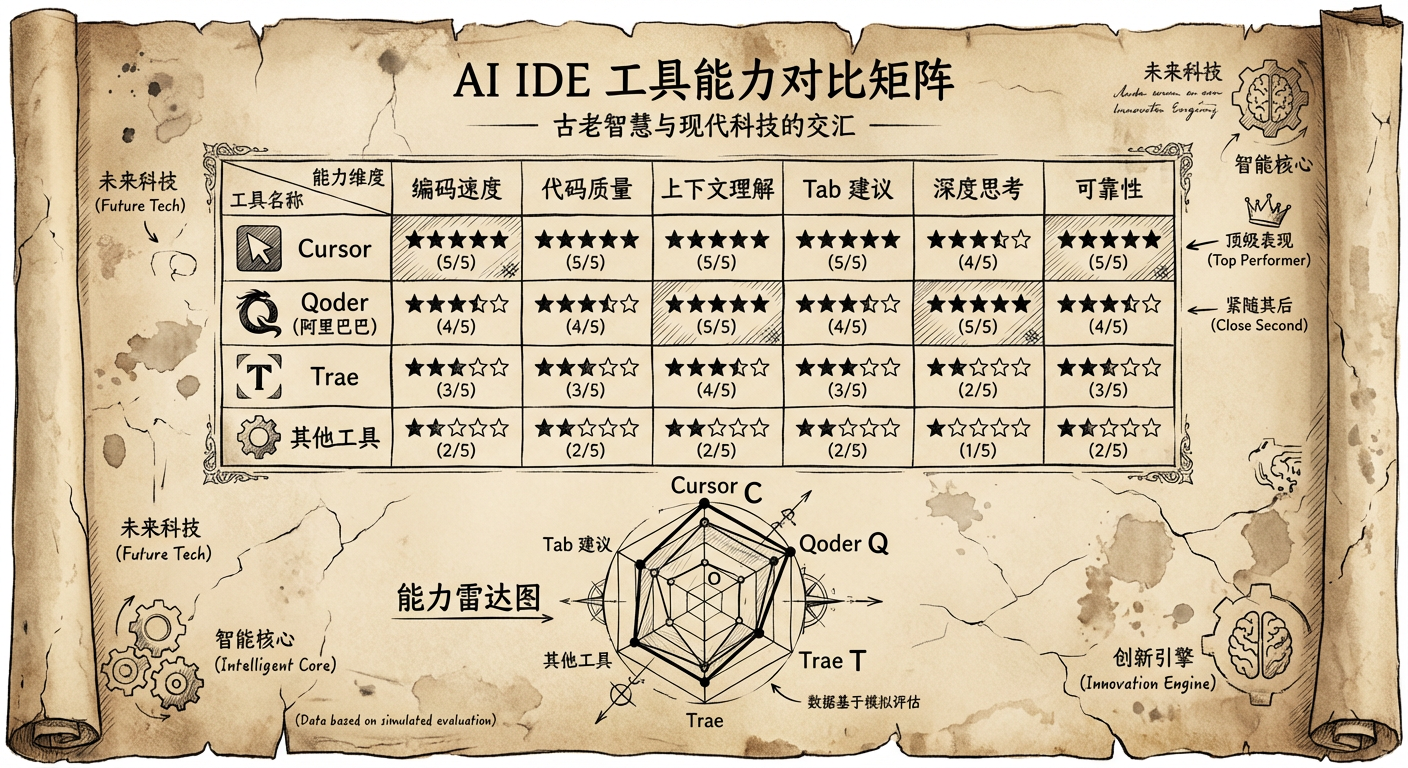
以下是我自己使用过的工具,综合主观评价:Cursor > Qoder (阿里自研 IDE) > Trae > 其他 。
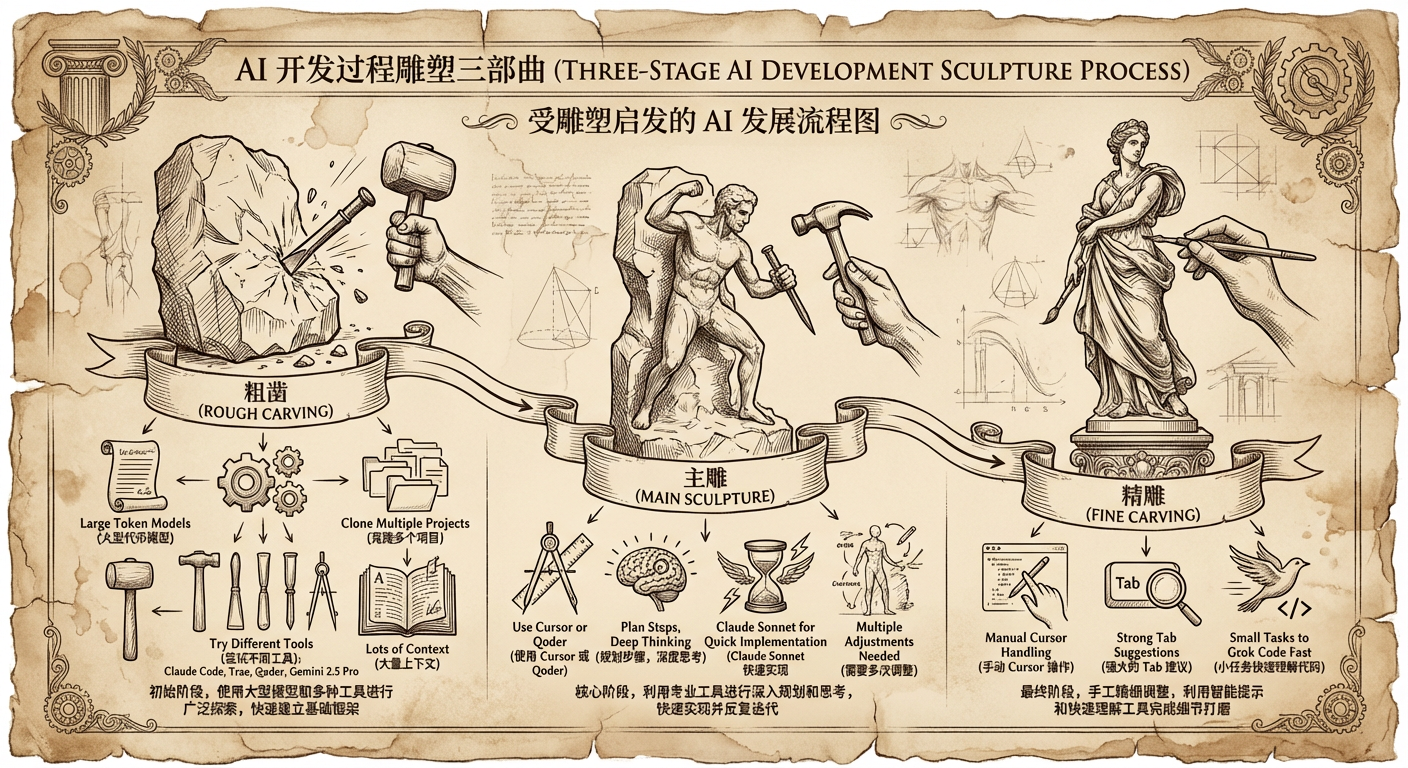
使用这些工具就像完成一件雕塑,用到不同的锤子、凿子、刮刀;AI 编码不是 3D 打印那样一次成型,而是 粗凿 → 主雕 → 精雕 的过程。
粗凿 最好 clone 多个项目,把 Claude Code、Trae、Qoder 都试一遍 。Gemini 2.5 Pro 注入更多 context 上下文,择优留用。主雕 Cursor 或 Qoder ,先规划步骤与任务,开启深度思考,用 Claude Sonnet 快速实现。精雕 Cursor 手动处理 ,因为它有更强的 Tab 提示能力。Grok Code Fast 模型,非常迅速且精准。
例:让小工验证
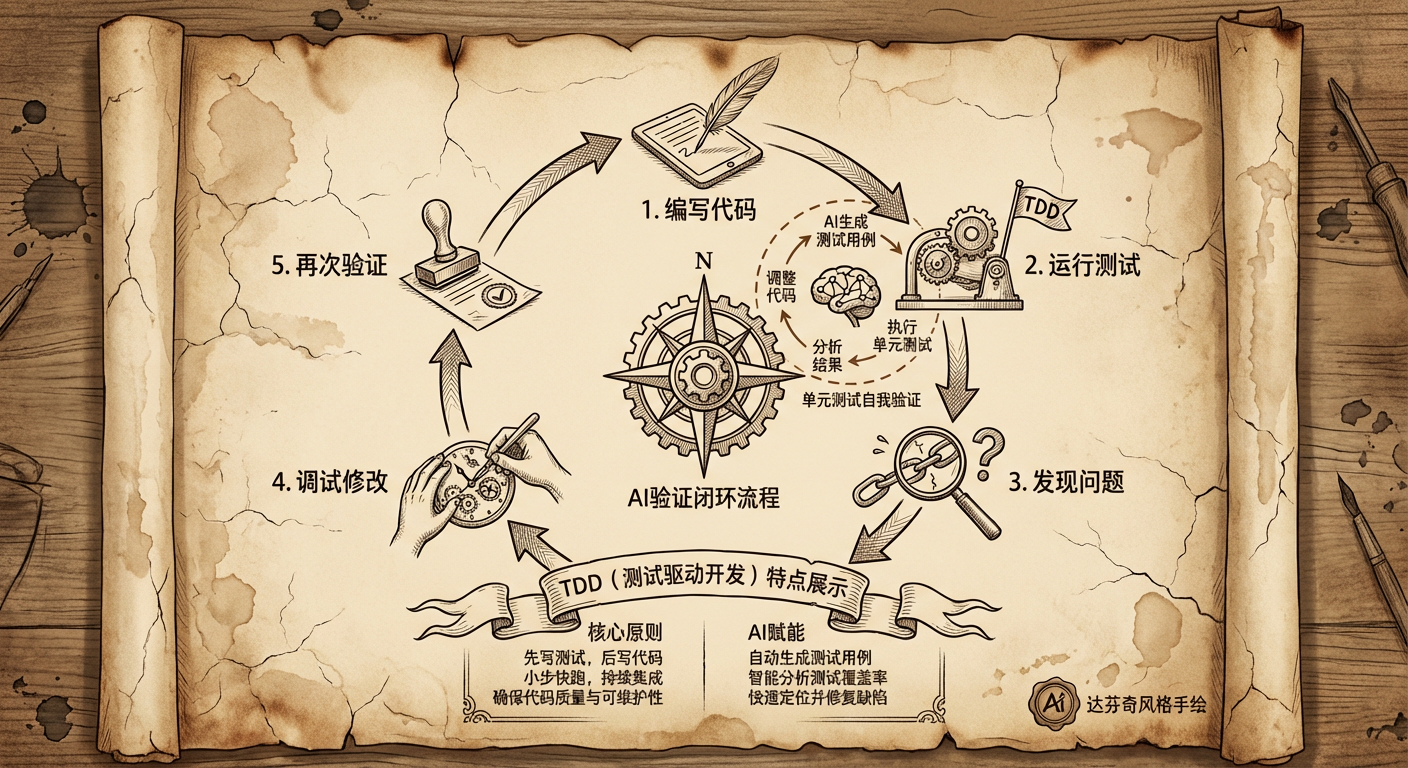
一个好的闭环结果验证,可以驱动 AI 无限自我循环直到完成任务。我曾经使用 AI 去处理一个测试完备的开源项目 PR,因为是开源项目,项目中已经有 150+ 的测试用例,在驱动 AI 完成任务的过程中要求 TDD 方式处理,中间大概跑了 1 个多小时,AI 会反复通过单元测试自我验证,然后调试修改,再验证,直到最后完全完成任务。
从这个角度上来讲,我认为 AI 在编写 Java 代码时会更具验证优势,Java 的强类型特性,编译通过基本可以解决大部分 BUG,这些配合 IDE 连通 Language Server 就可以做到相对较好的自我纠偏。而前端这一方面会相对较弱,许多对象定义缺少类型推断,页面样式又涉及到图像 AI 缺乏判断标准,导致在自我纠偏与验证的过程会相对麻烦。
另外一方面,AI 配合一些好的设计模式,再加上可以明确 TDD 的情况下,可以做许多”小而优雅”的封装。
举个具体的例子,在服务端中我们有许多上下游 HSF (内部 RPC 调用) 调用,为了更优雅地内聚相关逻辑,我们可能会将部分查询封装在各自的 Service 中,但这可能会导致同一个耗时 IO 被重复执行。好的办法是我们可以单独针对 Remote 调用做一个独立的 Service 封装,然后在该方法中处理好请求级缓存。想到这里,更优雅的办法是可以采用装饰器设计模式,对其做一个独立的注解封装,例如:
@ RequestCache ( key = "'remote-' + #serviceId + '-' + #params.hashCode()" , condition = "#params != null" , ignoreException = true ) public RemoteData callRemoteService ( String serviceId , Map < String , Object > params) { return remoteService . call (serviceId, params); } 这在 HTTP 请求相关的项目中有最佳实践,但在 HSF 调用时我却没找到相关资料,如果纯 if-else 又显得极不优雅。
于是,给 Claude 布置作业吧:要求完成上述用法的装饰器设计,严格按照 TDD 模式开发,具备容错降级能力…
例:招/薅 更多小工
一套前后端全栈干下来,会发现基础的套餐额度根本不够用。其实现在的 AI 编码真用起来不便宜,基础套餐基本在高强度使用下,一周就用完,所以基本需要看到 Max 套餐。这个时候就不得不想想在哪可以买到或者薅到更便宜的 Claude 来用。
所以针对不同小工的价格和计费方式,我们需要分配不同的任务给到他们以便 ROI 最大化,逐渐感觉自己变成资本家 🤦♂️
在目前的阶段,公司内部其实有非常多渠道可以拿到免费的 AI 资源,参考:内网 AI 白嫖手册 )
简单列举一下:
内部大模型平台提供的免费额度,你可以在这里薅到各种主流大模型,配合本地客户端或命令行工具可以作为日常杂活无限用的场景。 Qoder (阿里新发布的 IDE),限免阶段,是优秀的 AI 编程工具。 Aone Agent (智能研发 Agent),Agent 模式后台运行,与 Aone MCP、Code 平台打通,可选择仓库后通过编写任务清单,后台异步运行,完成任务后会通过消息通知或 MR 形式反馈,异步运行,潜力巨大。 总体来说,公司提供的能薅到的 AI 资源还是不少的,就看咱们能撬动多少了,薅到就是赚到 💰 虽然我是一个人,实际背后有 10 个 AI,10X 工程师本师 🦁
一人独角兽 在 AI 投资圈内,最近有一个比较热的词语,一人独角兽公司,并非是指一个人的独立创业者,而是指那些人数极少却带来极大利润的公司。
一人独角兽之路并非单纯比拼专业技能,而在于能否在心理认知、财务策略、市场洞察和持续迭代上全方位做好准备。换言之,真正成功的Solopreneur,不仅仅是一个技术达人或创意达人,更要是一个精通商业、善于自省并能够快速调整状态的“全能”经营者。
在当前日新月异的 AI 发展背景下,不用谈论 AI 现在还做不到什么,还代替不了什么。我的观点是,尽快让自己成长到更高维度的思维上,问问自己能撬动多少 AI,有了 AI 我可以做些什么以前做不到的事情 ,我现在一个月能用掉多少 Token。
永远给 AI 留出成长空间,比如今天 AI 的幻觉高、美商差,不一定需要大量规则限定,AI 基座的迭代速度比之前的互联网迭代速度还要快的多,曾经我们花费了大量人力、算力投入进 SD 方案,模特穿衣、抠图、换背景,速度慢成本高,新的端侧 AI 方案一出现把这个事直接干趴下。甚至可能端侧直接调用,就可以完成以前 200 人日研发出来的工程能力。
在这种时刻下,有更清晰与宏观的产品认知、架构设计、商业逻辑,能够思路清晰、边界明确对目标结果有明确认知的人才能驱动更大 AI 能力。人才能力模型会发生变化,生产关系也一定会有变化,公司中能否出现像“一人独角兽”类似概念的“超级单兵”,可能会是接下来相当长一段时间的话题。
马老师之前讲过,“今天能够定义清楚的东西都不是未来” 。
这句话现在给 AI,“今天能够定义清楚的东西都交给 AI”。
__
Agent 管理会变成一门学问吗?🤦♂️